





Python(基础)复刻文档
1.Python基础知识
计算机组成原理
1.1 什么是计算机?
计算机(computer)俗称电脑,是现代一种用于高速计算的电子机器,可以进行数值计算,又可以进行逻辑判断,还具有存储记忆功能,且能够按照程序的运行,自动、高速处理数据。
计算机是20世纪最先进的科学技术发明之一。
1.2 计算机是由什么组成的?
一个完整的计算机系统,是由硬件系统和软件系统两大部分组成的。
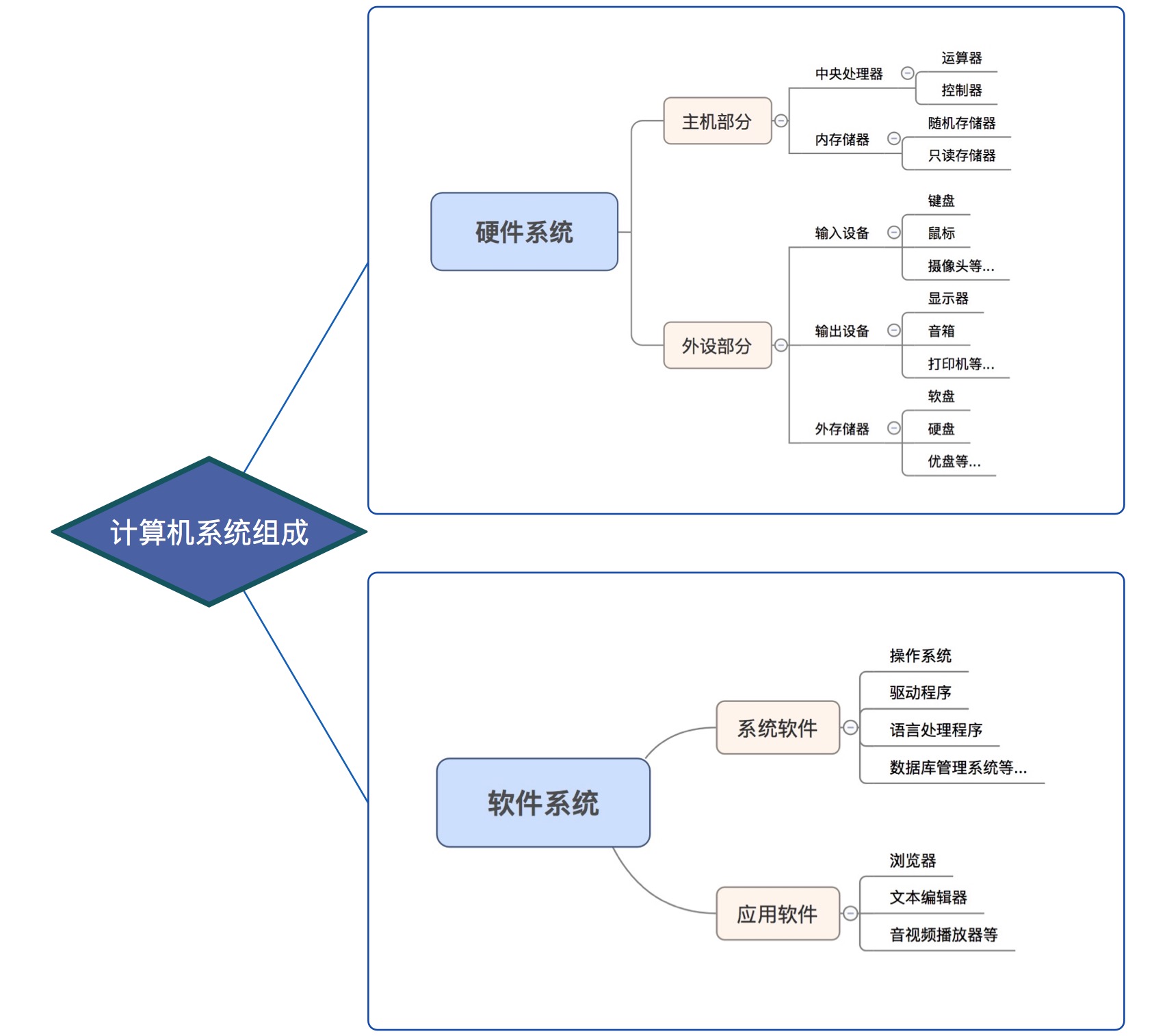
一、硬件系统:
主要分为主机和外设两部分,是指那些构成计算机系统的物理实体,它们主要由各种各样的电子器件和机电装置组成。
从ENIAC(世界上第一台计算机)到当前最先进的计算机,硬件系统的设计采用的都是 冯·诺依曼体系结构。
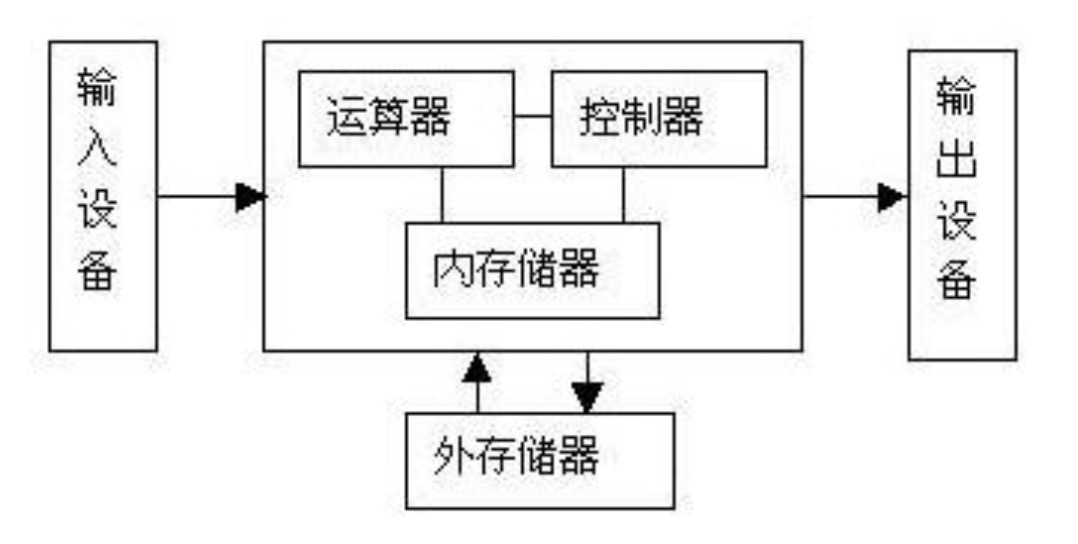
运算器: 负责数据的算术运算和逻辑运算,即数据的加工处理。
控制器: 是整个计算机的中枢神经,分析程序规定的控制信息,并根据程序要求进行控制,协调计算机各部分组件工作及内存与外设的访问等。运算器和控制器统称中央处理器(即CPU)
存储器: 实现记忆功能的部件,用来存储程序、数据和各种信号、命令等信息,并在需要时提供这些信息。
输入设备: 实现将程序、原始数据、文字、字符、控制命令或现场采集的数据等信息输入到计算机。
输出设备: 实现将计算机处理后生成的中间结果或最后结果(各种数据符号及文字或各种控制信号等信息)输出出来。
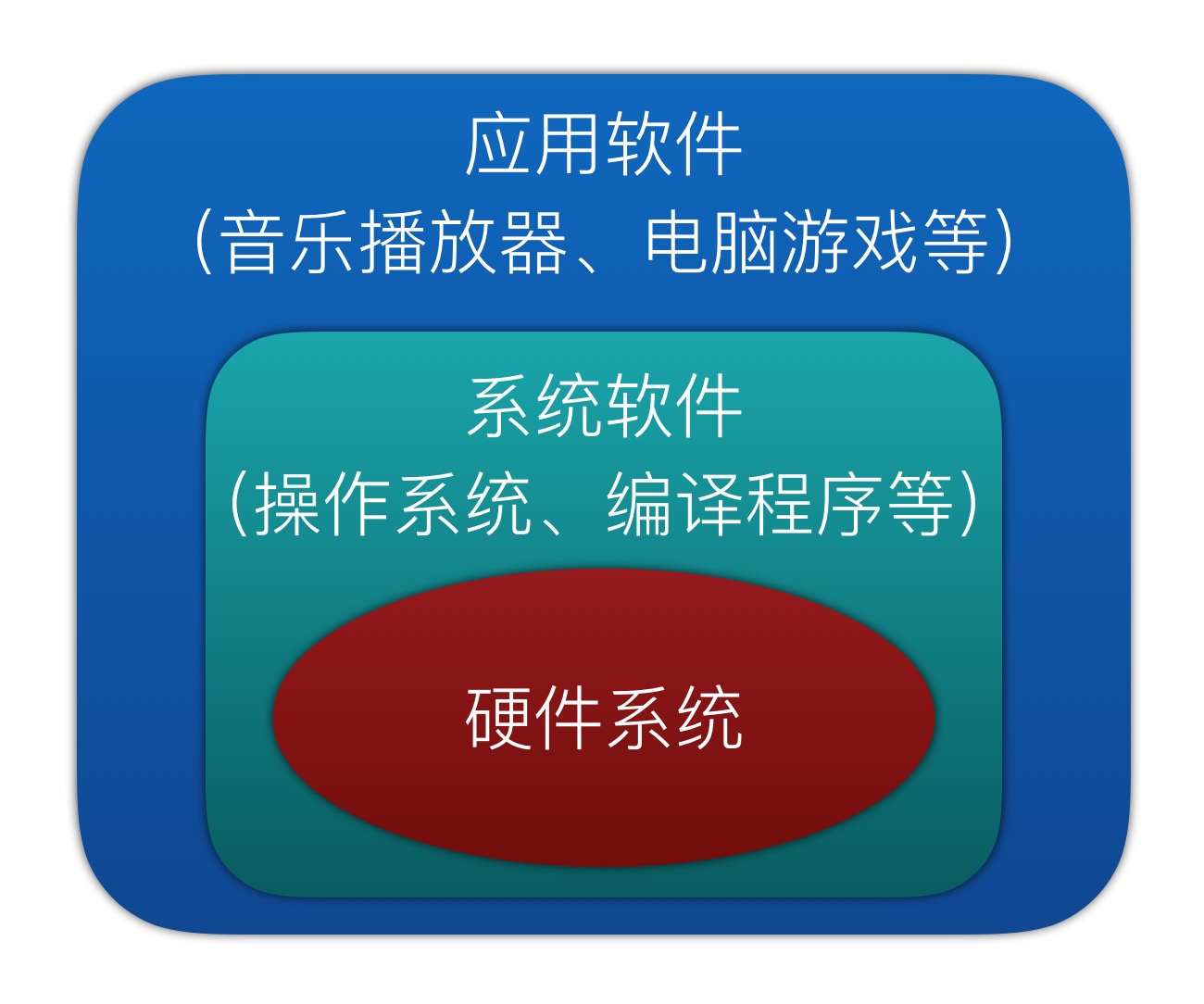
二、软件系统:
主要分为系统软件和应用软件,是指计算机证运行所需的各种各样的计算机程序。
系统软件的任务是既要保证计算机硬件的正常工作,又要使计算机硬件的性能得到充分发挥,并且为计算机用户提供一个比较直观、方便和友好的使用界面。
操作系统:是一种方便用户管理和控制计算机软硬件资源的系统软件,同时也是一个大型的软件系统,其功能复杂,体系庞大,在整个计算机系统中具有承上启下的地位。我们操作计算机实际上是通过操作系统来进行的,它是所有软件的基础和核心。
语言处理程序:也称为编译程序,作用是把程序员用某种编程语言(如Python)所编写的程序,翻译成计算机可执行的机器语言。机器语言也被称为机器码,是可以通过CPU进行分析和执行的指令集。
三、计算机是如何处理程序的?
按照冯·诺依曼存储程序的原理,计算机的工作流程大致如下:
- 用户打开程序,程序开始执行;
- 操作系统将程序内容和相关数据送入计算机的内存;
- CPU根据程序内容从内存中读取指令;
- CPU分析、处理指令,并为取下一条指令做准备;
- 取下一条指令并分析、处理,如此重复操作,直至执行完程序中全部指令,最后将计算的结果放入指令指定的存储器地址中。
四、编程语言是什么?
是用来定义 计算机程序 的形式语言。我们通过编程语言来编写程序代码,再通过语言处理程序执行向计算机发送指令,让计算机完成对应的工作。
简单来说,编程语言就是人类和计算机进行交流的语言。
五、什么是Python?
Python就是一门编程语言,而且是现在世界上最流行的编程语言之一。
1.2 认识python(了解)
一、Python发展背景
Python的作者,Guido von Rossum(吉多·范·罗苏姆,中国Python程序员都叫他 龟叔),荷兰人。1982年,龟叔从阿姆斯特丹大学获得了数学和计算机硕士学位。然而,尽管他算得上是一位数学家,但他更加享受计算机带来的乐趣。用他的话说,虽然拥有数学和计算机双料资质,他总趋向于做计算机相关的工作,并热衷于做任何和编程相关的事情。
在那个时候,龟叔接触并使用过诸如Pascal、C、Fortran等语言。这些语言的基本设计原则是让机器能更快运行。在80年代,虽然IBM和苹果已经掀起了个人电脑浪潮,但这些个人电脑的配置很低。比如早期的Macintosh,只有8MHz的CPU主频和128KB的RAM,一个大的数组就能占满内存。所有的编译器的核心是做优化,以便让程序能够运行。为了增进效率,语言也迫使程序员像计算机一样思考,以便能写出更符合机器口味的程序。在那个时代,程序员恨不得用手榨取计算机每一寸的能力。有人甚至认为C语言的指针是在浪费内存。至于动态类型,内存自动管理,面向对象…… 别想了,那会让你的电脑陷入瘫痪。

这种编程方式让龟叔感到苦恼。龟叔知道如何用C语言写出一个功能,但整个编写过程需要耗费大量的时间,即使他已经准确的知道了如何实现。他的另一个选择是shell。Bourne Shell作为UNIX系统的解释器已经长期存在。UNIX的管理员们常常用shell去写一些简单的脚本,以进行一些系统维护的工作,比如定期备份、文件系统管理等等。shell可以像胶水一样,将UNIX下的许多功能连接在一起。许多C语言下上百行的程序,在shell下只用几行就可以完成。然而,shell的本质是调用命令。它并不是一个真正的语言。比如说,shell没有数值型的数据类型,加法运算都很复杂。总之,shell不能全面的调动计算机的功能。
龟叔希望有一种语言,这种语言能够像C语言那样,能够全面调用计算机的功能接口,又可以像shell那样,可以轻松的编程。ABC语言让龟叔看到希望。ABC是由荷兰的数学和计算机研究所开发的。龟叔在该研究所工作,并参与到ABC语言的开发。ABC语言以教学为目的。与当时的大部分语言不同,ABC语言的目标是“让用户感觉更好”。ABC语言希望让语言变得容易阅读,容易使用,容易记忆,容易学习,并以此来激发人们学习编程的兴趣。比如下面是一段来自Wikipedia的ABC程序,这个程序用于统计文本中出现的词的总数:
1
2
3
4
5
6
7HOW TO RETURN words document:
PUT {} IN collection
FOR line IN document:
FOR word IN split line:
IF word not.in collection:
INSERT word IN collection
RETURN collectionHOW TO用于定义一个函数。一个Python程序员应该很容易理解这段程序。ABC语言使用冒号和缩进来表示程序块。行 尾没有分号。for和if结构中也没有括号() 。赋值采用的是PUT,而不是更常见的等号。这些改动让ABC程序读起来像一段文字。
尽管已经具备了良好的可读性和易用性,ABC语言最终没有流行起来。在当时,ABC语言编译器需要比较高配置的电脑才能运行。而这些电脑的使用者通常精通计算机,他们更多考虑程序的效率,而非它的学习难度。除了硬件上的困难外,ABC语言的设计也存在一些致命的问题:
- 可拓展性差。ABC语言不是模块化语言。如果想在ABC语言中增加功能,比如对图形化的支持,就必须改动很多地方。
- 不能直接进行IO。ABC语言不能直接操作文件系统。尽管你可以通过诸如文本流的方式导入数据,但ABC无法直接读写文 件。输入输出的困难对于计算机语言来说是致命的。你能想像一个打不开车门的跑车么?
- 过度革新。ABC用自然语言的方式来表达程序的意义,比如上面程序中的HOW TO 。然而对于程序员来说,他们更习惯 用function或者define来定义一个函数。同样,程序员更习惯用等号来分配变量。尽管ABC语言很特别,但学习难度 也很大。
- 传播困难。ABC编译器很大,必须被保存在磁带上。当时龟叔在访问的时候,就必须有一个大磁带来给别人安装ABC编 译器。 这样,ABC语言就很难快速传播。
1989年,为了打发圣诞节假期,龟叔开始写Python语言的编译器。Python这个名字,来自龟叔所挚爱的电视剧Monty Python’s Flying Circus( 大蟒蛇飞行马戏团)。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。龟叔作为一个语言设计爱好者,已经有过设计语言的尝试。这一次,也不过是一次纯粹的hacking行为。
二、Python语言的诞生
1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了 :类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
Python语法很多来自C,但又受到ABC语言的强烈影响。来自ABC语言的一些规定直到今天还富有争议,比如强制缩进。 但这些语法规定让Python容易读。另一方面,Python聪明的选择服从一些惯例,特别是C语言的惯例,比如回归等号赋值。龟叔认为,如果“常识”上确立的东西,没有必要过度纠结。
Python从一开始就特别在意可拓展性。Python可以在多个层次上拓展。从高层上,你可以直接引入. py文件。在底层,你可以引用C语言的库。Python程序员可以快速的使用Python写. py文件作为拓展模块。但当性能是考虑的重要因素时,Python程序员可以深入底层,写C程序,编译为.so文件引入到Python中使用。Python就好像是使用钢构建房一样,先规定好大的框架。而程序员可以在此框架下相当自由的拓展或更 改。
最初的Python完全由龟叔本人开发。Python得到龟叔同事的欢迎。他们迅速的反馈使用意见,并参与到Python的改进。龟叔和一些同事构成Python的核心团队。他们将自己大部分的业余时间用于hack Python。随后,Python拓 展到研究所之外。Python将许多机器层面上的细节隐藏,交给编译器处理,并凸显出逻辑层面的编程思考。Python程 序员可以花更多的时间用于思考程序的逻辑,而不是具体的实现细节。这一特征吸引了广大的程序员。Python开始流行。

人生苦短,我用python
- 计算机硬件越来越强大,Python又容易使用,所以许多人开始转向Python。龟叔维护了一个mail list,Python用户就通过邮件进行交流。Python用户来自许多领域,有不同的背景,对Python也有不同的需求。Python相当的开放,又容 易拓展,所以当用户不满足于现有功能,很容易对Python进行拓展或改造。随后,这些用户将改动发给龟叔,并由龟叔决定是否将新的特征加入到Python或者标准库中。如果代码能被纳入Python自身或者标准库,这将极大的荣誉。由于龟叔至高无上的决定权,他因此被称为“终身的仁慈独裁者”。
- Python以及其标准库的功能强大。这些是整个社区的贡献。Python的开发者来自不同领域,他们将不同领域的优点带给Python。比如Python标准库中的正则表达是参考Perl,而lambda, map, filter, reduce等函数参考了Lisp。Python本身的一些功能以及大部分的标准库来自于社区。Python的社 区不断扩大,进而拥有了自己的newsgroup,网站,以及基金。从Python 2.0开始,Python也从mail list的开发方式,转为完全开源的开发方式。社区气氛已经形成,工作被整个社区分担,Python也获得了更加高速的发展。
- 到今天,Python的框架已经确立。Python语言以对象为核心组织代码,支持多种编程范式,采用动态类型,自动进行内存回收。Python支持解释运行,并能调用C库进行拓展。Python有强大的标准库。由于标准库的体系已经稳定,所以Python的生态系统开始拓展到第三方包。这些包,如Django、web.py、wxpython、numpy、matplotlib、PIL,将Python升级成了物种丰富的热带雨林。
- Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。Python在TIOBE排行榜中排行第八,它是Google的第三大开发语言,Dropbox的基础语言,豆瓣的服务器语言。Python的发展史可以作为一个代表,带给我许多启示。
- 在Python的开发过程中,社区起到了重要的作用。龟叔自认为自己不是全能型的程序员,所以他只负责制订框架。如果问题太复杂,他会选择绕过去,也就是cut the corner。这些问题最终由社区中的其他人解决。社区中的人才是异常丰富的,就连创建网站,筹集基金这样与开发稍远的事情,也有人乐意于处理。如今的项目开发越来越复杂,越来越庞大,合作以及开放的心态成为项目最终成功的关键。
- Python从其他语言中学到了很多,无论是已经进入历史的ABC,还是依然在使用的C和Perl,以及许多没有列出的其他 语言。可以说,Python的成功代表了它所有借鉴的语言的成功。同样,Ruby借鉴了Python,它的成功也代表了Python某些方面的成功。每个语言都是混合体,都有它优秀的地方,但也有各种各样的缺陷。同时,一个语言“好与不好”的评判,往往受制于平台、硬件、时代等等外部原因。程序员经历过许多语言之争。其实,以开放的心态来接受各个语言,说不定哪一天,程序员也可以如龟叔那样,混合出自己的语言。
三、关键点常识
- Python的发音与拼写
- Python的作者是Guido van Rossum(龟叔)
- Python正式诞生于1991年
- Python的解释器如今有多个语言实现,我们常用的是CPython(官方版本的C语言实现),其他还有Jython(可以运行在Java平台)、IronPython(可以运行在.NET和Mono平台)、PyPy(Python实现的,支持JIT即时编译)
- Python目前有两个版本,Python2和Python3,最新版分别为2.7.13和3.6.2
- Life is shot, you need Python. 人生苦短,我用Python。
(2017年8月,TIOBE 编程语言流行排行榜)
四、Python优缺点
优点
- 简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样,尽管这个英语的要求非常严格!Python的这种伪代码本质是它最大的优点之一。它使你能够专注于解决问题而不是去搞明白语言本身。
- 易学:就如同你即将看到的一样,Python极其容易上手。前面已经提到了,Python有极其简单的语法。
- 免费、开源:Python是FLOSS(自由/开放源码软件)之一。简单地说,你可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。这是为什么Python如此优秀的原因之一——它是由一群希望看到一个更加优秀的Python的人创造并经常改进着的。
- 高层语言:当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
- 可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就可以在下述任何平台上面运行。这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE甚至还有PocketPC、Symbian以及Google基于linux开发的Android平台!
- 解释型语言:一个用编译型语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程序。在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接转载正确的库等等,所有这一切使得使用Python更加简单。由于你只需要把你的Python程序拷贝到另外一台计算机上,它就可以工作了,这也使得你的Python程序更加易于移植。
- 面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。与其他主要的语言如C++和Java相比,Python以一种非常强大又简单的方式实现面向对象编程。
- 可扩展性:如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 丰富的库:Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。记住,只要安装了Python,所有这些功能都是可用的。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
- 规范的代码:Python采用强制缩进的方式使得代码具有极佳的可读性。
缺点
Python语言非常完善,没有明显的短板和缺点,唯一的缺点就是执行效率慢,这个是解释型语言所通有的,同时这个缺点也将被计算机越来越强大的性能所弥补。
五、Python应用场景
Web应用开发
Python经常被用于Web开发。比如,通过mod_wsgi模块,Apache可以运行用Python编写的Web程序。Python定义了WSGI标准应用接口来协调Http服务器与基于Python的Web程序之间的通信。一些Web框架,如Django,TurboGears,web2py,Zope等,可以让程序员轻松地开发和管理复杂的Web程序。
操作系统管理、服务器运维的自动化脚本
在很多操作系统里,Python是标准的系统组件。 大多数Linux发行版以及NetBSD、OpenBSD和Mac OS X都集成了Python,可以在终端下直接运行Python。有一些Linux发行版的安装器使用Python语言编写,比如Ubuntu的Ubiquity安装器,Red Hat Linux和Fedora的Anaconda安装器。Gentoo Linux使用Python来编写它的Portage包管理系统。Python标准库包含了多个调用操作系统功能的库。通过pywin32这个第三方软件 包,Python能够访问Windows的COM服务及其它Windows API。使用IronPython,Python程序能够直接调用.Net Framework。一般说来,Python编写的系统管理脚本在可读性、性能、代码重用度、扩展性几方面都优于普通的shell脚本。
网络爬虫
Python有大量的HTTP请求处理库和HTML解析库,并且有成熟高效的爬虫框架Scrapy和分布式解决方案scrapy-redis,在爬虫的应用方面非常广泛。
科学计算
NumPy、SciPy、Pandas、Matplotlib可以让Python程序员编写科学计算程序。
桌面软件
PyQt、PySide、wxPython、PyGTK是Python快速开发桌面应用程序的利器。
服务器软件(网络软件)
Python对于各种网络协议的支持很完善,因此经常被用于编写服务器软件、网络爬虫。第三方库Twisted支持异步网络编程和多数标准的网络协议(包含客户端和服务器),并且提供了多种工具,被广泛用于编写高性能的服务器软件。
游戏
很多游戏使用C++编写图形显示等高性能模块,而使用Python或者Lua编写游戏的逻辑、服务器。相较于Python,Lua的功能更简单、体积更小;而Python则支持更多的特性和数据类型。
构思实现,产品早期原型和迭代
Google、NASA、Facebook都在内部大量地使用Python。
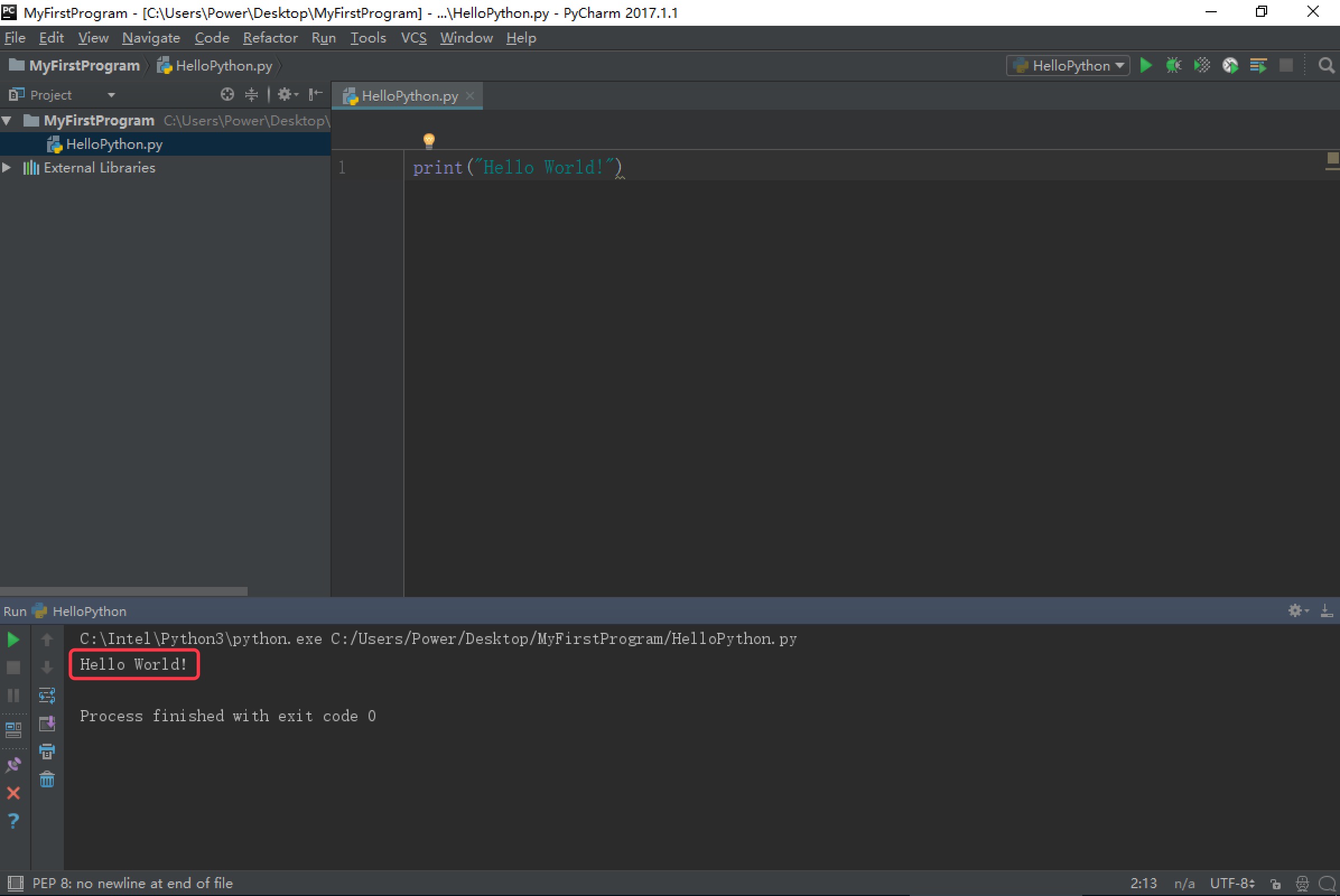
1.3 第一个python程序
使用Pycharm编写第一个python程序
打开 Pycharm,选择
Create New Project,创建一个新项目
选择
Pure Python表示创建一个纯Python程序项目,Location表示该项目保存的路径,Interpreter表示使用的Python解释器版本,最后点击Create创建项目。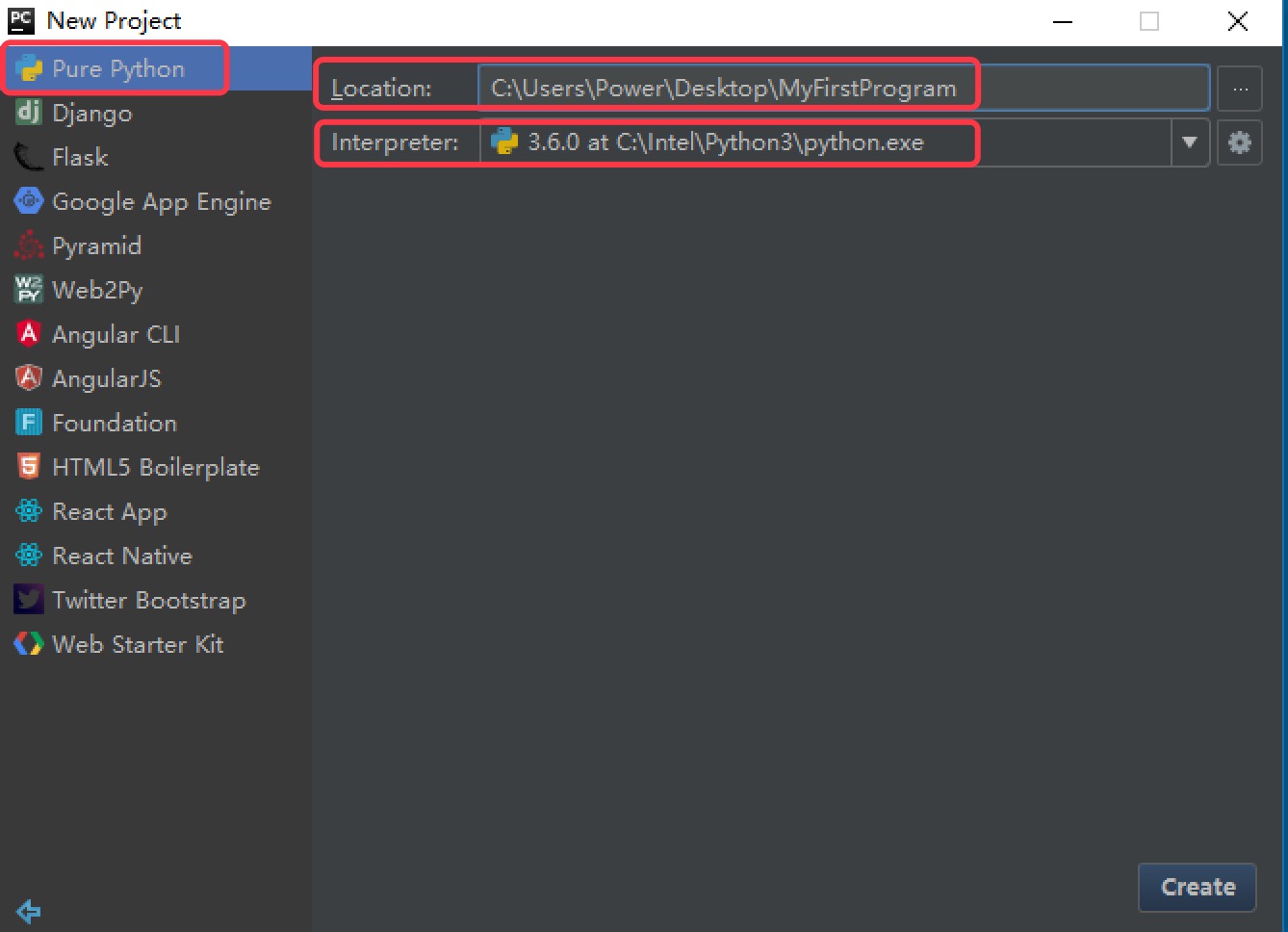
右击项目,选择
New,再选择Python File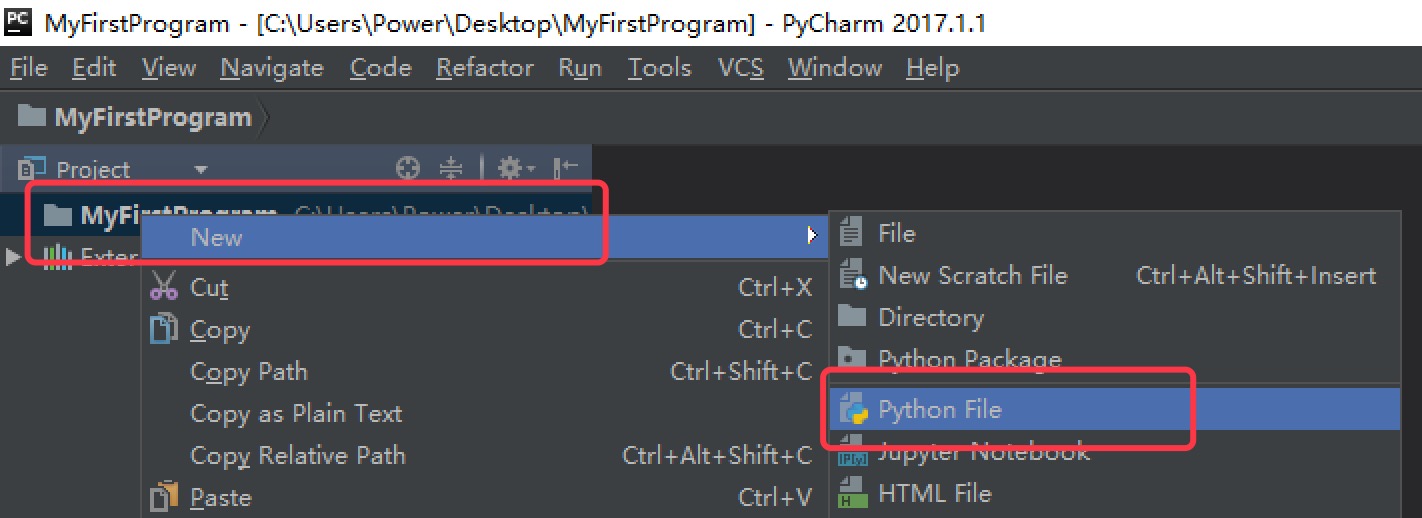
在弹出的对话框中输入的文件名HelloPython,点击
OK,表示创建一个Python程序的文本文件,文本文件后缀名默认.py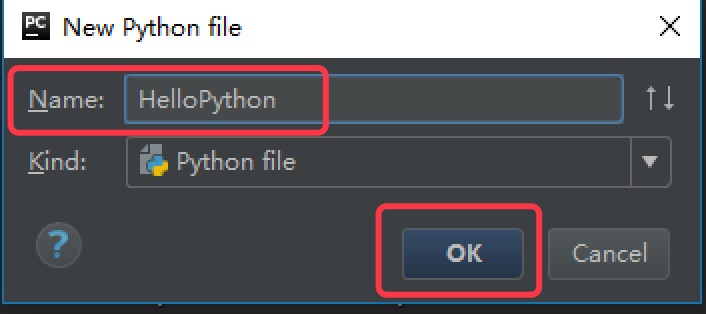
输入以下代码,并右击空白处,选择
Run运行,表示打印一个字符串”Hello World!”。1
print("Hello World!")
```
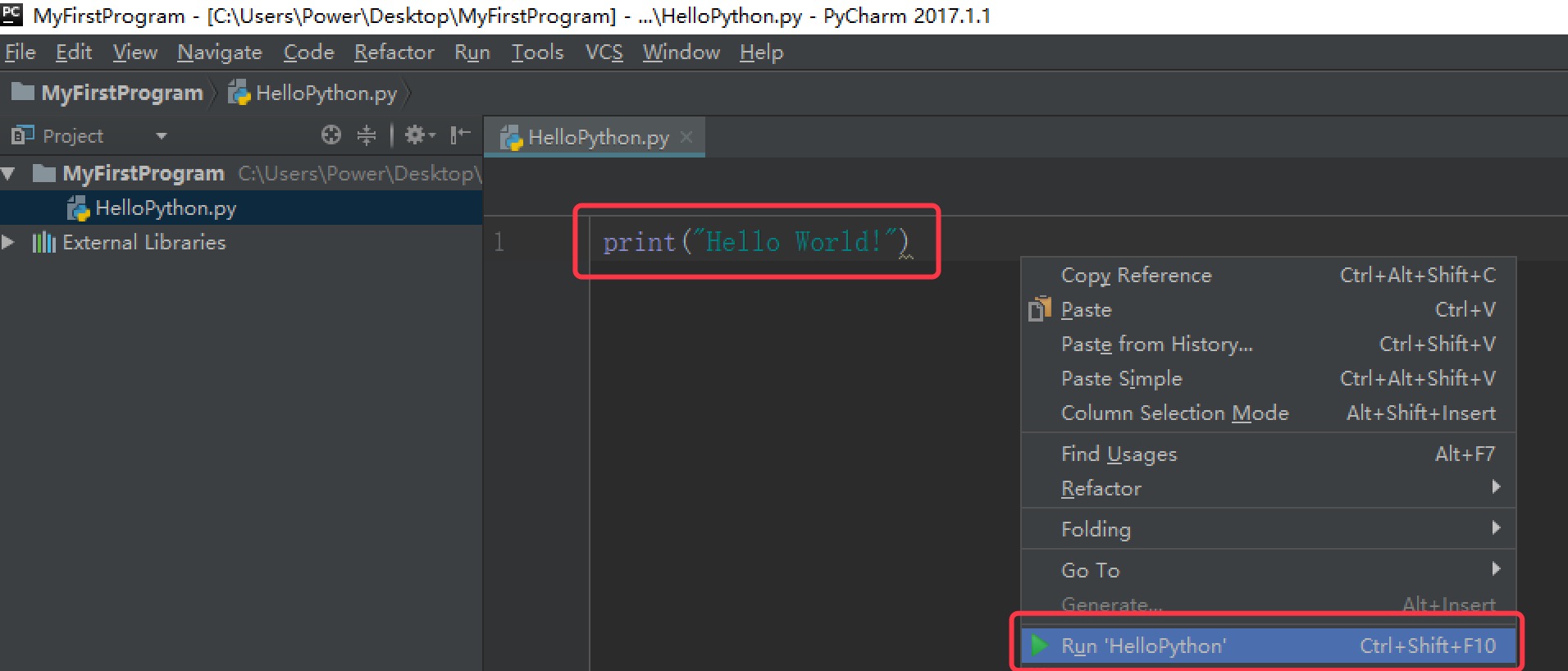
运行成功后,Pycharm Console窗口将显示我们的输出结果。
练一练
要求:编写一个程序,输出czxy.com
1.4 注释
1. 注释的引入
<1> 看以下程序示例(未使用注释)

<2> 看以下程序示例(使用注释)
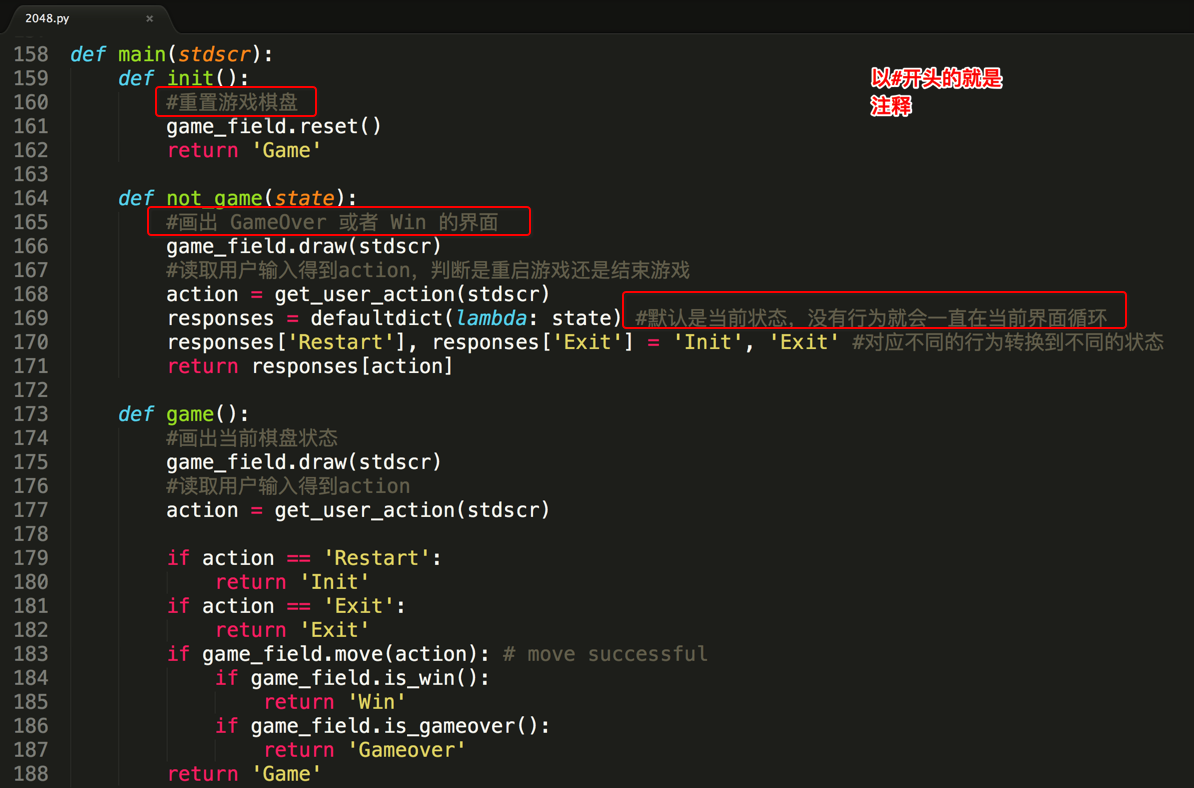
<3> 小总结(注释的作用)
- 通过用自己熟悉的语言,在程序中对某些代码进行标注说明,这就是注释的作用,能够大大增强程序的可读性
2. 注释的分类
<1> 单行注释
以#开头,#右边的所有东西当做说明,而不是真正要执行的程序,起辅助说明作用
1 | # 我是注释,可以在里写一些功能说明之类的哦 |
<2> 多行注释
1 | ''' |
<3> python程序中,中文支持
python3中,是默认支持中文的,但是在python2中就需要一定的额外操作才可以
python2中,如果直接在程序中用到了中文,比如
1 | print('你好') |
如果直接运行输出,程序会出错:

解决的办法为:在程序的开头写入如下代码,这就是中文注释
1 | #coding=utf-8 |
修改之后的程序:
1 | #coding=utf-8 |
运行结果:
1 | 你好 |
注意:
在python的语法规范中推荐使用的方式:
1 | # -*- coding:utf-8 -*- |
1.5 变量
变量以及类型
<1>变量的定义
在程序中,有时我们需要对2个数据进行求和,那么该怎样做呢?
大家类比一下现实生活中,比如去超市买东西,往往咱们需要一个菜篮子,用来进行存储物品,等到所有的物品都购买完成后,在收银台进行结账即可
如果在程序中,需要把2个数据,或者多个数据进行求和的话,那么就需要把这些数据先存储起来,然后把它们累加起来即可
在Python中,存储一个数据,需要一个叫做变量的东西,如下示例:
1 | num1 = 100 #num1就是一个变量,就好一个小菜篮子 |
- 说明:
- 所谓变量,可以理解为
菜篮子,如果需要存储多个数据,最简单的方式是有多个变量,当然了也可以使用一个 - 程序就是用来处理数据的,而变量就是用来存储数据的
- 所谓变量,可以理解为
想一想:我们应该让变量占用多大的空间,保存什么样的数据?
<2>变量的类型
生活中的“类型”的例子:

程序中:
为了更充分的利用内存空间以及更有效率的管理内存,变量是有不同的类型的,如下所示:

怎样知道一个变量的类型呢?
- 在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要咱们开发者主动的去说明它的类型,系统会自动辨别
- 可以使用type(变量的名字),来查看变量的类型
1.6 标识符和关键字
标识符和关键字
<1>标识符
什么是标识符,看下图:
开发人员在程序中自定义的一些符号和名称
标识符是自己定义的,如变量名 、函数名等
<2>标识符的规则
标识符由字母、下划线和数字组成,且数字不能开头
思考:下面的标识符哪些是正确的,哪些不正确为什么
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from#12
my_Boolean
my-Boolean
Obj2
2ndObj
myInt
test1
Mike2jack
My_tExt
_test
test!32
haha(da)tt
int
jack_rose
jack&rose
GUI
G.U.I
python中的标识符是区分大小写的
<3>命名规则
见名知意
起一个有意义的名字,尽量做到看一眼就知道是什么意思(提高代码可 读性) 比如: 名字 就定义为 name , 定义学生 用 student
驼峰命名法

小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:myName、aDog
大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:FirstName、LastName
还有一种命名法是用下划线“_”来连接所有的单词,比如send_buf,
Python的命令规则遵循PEP8标准,这个在后面会慢慢讲到。
<4>关键字
什么是关键字
python一些具有特殊功能的标识符,这就是所谓的关键字
关键字,是python已经使用的了,所以不允许开发者自己定义和关键字相同的名字的标识符
查看关键字:
1 | and as assert break class continue def del |
可以在Python Shell通过以下命令进行查看当前系统中python的关键字
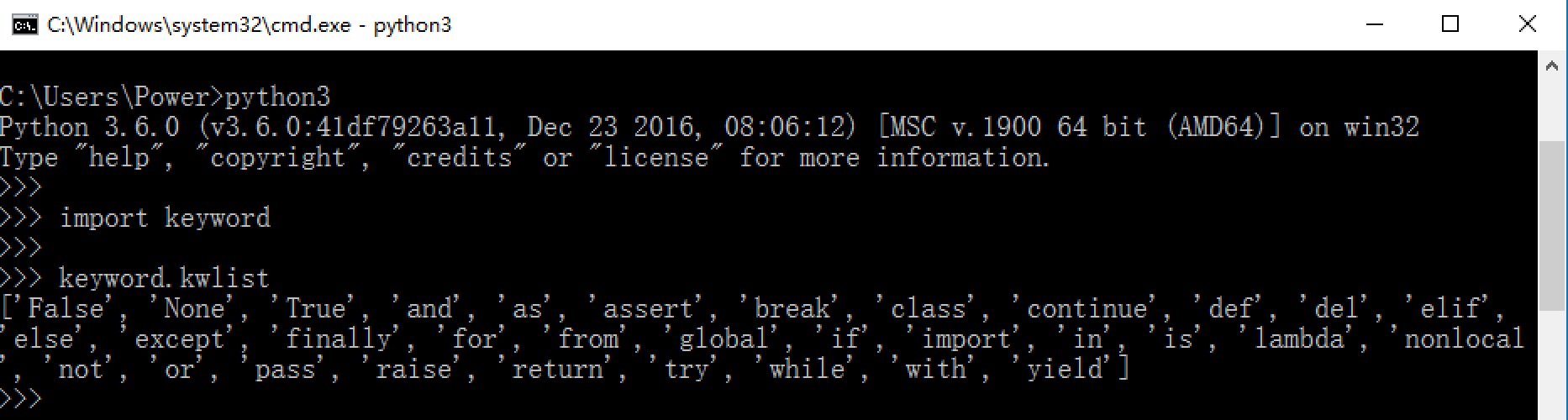
1 | import keyword |
或者

1 | >>> help('keywords') |
关键字的学习以及使用,咱们会在后面的课程中依一一进行学习。
1.7 输出
输出
1. 普通的输出
生活中的“输出”



软件中的“输出”
python中变量的输出
1 | # 打印提示 |
2. 格式化输出
<1>格式化操作的目的
比如有以下代码:
1 | pirnt("我今年10岁") |
想一想:
在输出年龄的时候,用了多次”我今年xx岁”,能否简化一下程序呢???
答:
字符串格式化
<2>什么是格式化
看如下代码:
1 | age = 10 |
在程序中,看到了%这样的操作符,这就是Python中格式化输出。
1 | age = 18 |
<3>常用的格式符号
下面是完整的,它可以与%符号使用列表:
| 格式符号 | 转换 |
|---|---|
| %c | 字符 |
| %s | 字符串 |
| %d | 有符号十进制整数 |
| %u | 无符号十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数(小写字母0x) |
| %X | 十六进制整数(大写字母0X) |
| %f | 浮点数 |
| %e | 科学计数法(小写’e’) |
| %E | 科学计数法(大写“E”) |
| %g | %f和%e 的简写 |
| %G | %f和%E的简写 |
3. 换行输出
在输出的时候,如果有\n那么,此时\n后的内容会在另外一行显示
1 | print("1234567890-------") # 会在一行显示 |
4. 练一练
- 编写代码完成以下名片的显示
1 | ==========我的名片========== |
1.8 输入
1.输入

咱们在银行ATM机器前取钱时,肯定需要输入密码,对不?
那么怎样才能让程序知道咱们刚刚输入的是什么呢??
大家应该知道了,如果要完成ATM机取钱这件事情,需要先从键盘中输入一个数据,然后用一个变量来保存,是不是很好理解啊
1.1 raw_input()
在Python中,获取键盘输入的数据的方法是采用 raw_input 函数(至于什么是函数,咱们以后的章节中讲解),那么这个 raw_input 怎么用呢?
看如下示例:
1 | password = raw_input("请输入密码:") |
运行结果:

注意:
- raw_input()的小括号中放入的是,提示信息,用来在获取数据之前给用户的一个简单提示
- raw_input()在从键盘获取了数据以后,会存放到等号右边的变量中
- raw_input()会把用户输入的任何值都作为字符串来对待
1.2 在python3 中 叫做input()
input()函数与raw_input()类似,但其接受的输入必须是表达式。
1 | password = input('请输入你的密码') |
注意input() 输入的数据 都是字符串类型
1.3 完成课上名片的案例
1.9 运算符
python支持以下几种运算符
1. 算术运算符
下面以a=10 ,b=20为例进行计算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | b / a 输出结果 2 |
| // | 取整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取余 | 返回除法的余数 b % a 输出结果 0 |
| ** | 指数 | a**b 为10的20次方, 输出结果 100000000000000000000 |
注意:混合运算时,优先级顺序为:
**高于*/%//高于+-,为了避免歧义,建议使用()来处理运算符优先级。并且,不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算。
1 | 10 + 5.5 * 2 |
2. 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | 把 = 号右边的结果 赋给 左边的变量,如 num = 1 + 2 * 3,结果num的值为7 |
1 | # 单个变量赋值 |
- 复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
1.10 数据类型转换
| 函数 | 说明 |
|---|---|
| int(x [,base ]) | 将x转换为一个整数 |
| float(x ) | 将x转换为一个浮点数 |
| complex(real [,imag ]) | 创建一个复数,real为实部,imag为虚部 |
| str(x ) | 将对象 x 转换为字符串 |
| repr(x ) | 将对象 x 转换为表达式字符串 |
| eval(str ) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s ) | 将序列 s 转换为一个元组 |
| list(s ) | 将序列 s 转换为一个列表 |
| chr(x ) | 将一个整数转换为一个Unicode字符 |
| ord(x ) | 将一个字符转换为它的ASCII整数值 |
| hex(x ) | 将一个整数转换为一个十六进制字符串 |
| oct(x ) | 将一个整数转换为一个八进制字符串 |
| bin(x ) | 将一个整数转换为一个二进制字符串 |
举例
1 | # int(): 将数据转换为 int 类型 |
附录:常用字符与ASCII码对照表

2 判断语句和循环语句
2.1 判断语句介绍
生活中的判断场景
火车站安检

上网吧

密码判断

小总结:
- 如果某些条件满足,才能做某件事情;条件不满足时,则不能做,这就是所谓的判断。
- 不仅生活中有,在软件开发中”判断”功能也经常会用到
2.2 if语句
<1>if判断语句介绍
- if语句是用来进行判断的,其使用格式如下:
1 | if 要判断的条件: |
- demo1:(demo的中文意思:演示、案例)
1 | age = 30 |
- 运行结果:
1 | ------if判断开始------ |
- demo2:
1 | age = 16 |
- 运行结果:
1 | ------if判断开始------ |
小总结:
- 以上2个demo仅仅是age变量的值不一样,导致结果却不同;能够看得出if判断语句的作用:就是当满足一定条件时才会执行代码块语句,否则就不执行代码块语句。
- 注意:代码的缩进为一个tab键,或者4个空格
<2>练一练
1.要求:从键盘获取自己的年龄,判断是否大于或者等于18岁,如果满足就输出“哥,已成年,网吧可以去了”
- 使用input从键盘中获取数据,并且存入到一个变量中
- 使用if语句,来判断 age>=18是否成立
2.编写代码,1-7七个数字,分别代表周一到周日,如果输入的数字是6或7,输出“周末”。
<3>想一想
- 判断age大于或者等于18岁使用的是 >=,如果是其他判断,还有哪些呢?
2.3 比较、关系运算符
<1> 比较(即关系)运算符
python中的比较运算符如下表
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果是则条件变为真。 | 如a=3,b=3,则(a == b) 为 True |
| != | 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 | 如a=1,b=3,则(a != b) 为 True |
| > | 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 | 如a=7,b=3,则(a > b) 为 True |
| < | 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 | 如a=7,b=3,则(a < b) 为 False |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3,则(a >= b) 为 True |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3,则(a <= b) 为 True |
1 | ## 关系运算符 |
<2> 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与”:如果 x 为 False,x and y 返回 False,否则它返回 y 的值。 | True and False, 返回 False。 |
| or | x or y | 布尔”或”:如果 x 是 True,它返回 True,否则它返回 y 的值。 | False or True, 返回 True。 |
| not | not x | 布尔”非”:如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not True 返回 False, not False 返回 True |
1 | ## 逻辑运算符 |
2.4 if-else
if-else
想一想:在使用if的时候,它只能做到满足条件时要做的事情。那万一需要在不满足条件的时候,做某些事,该怎么办呢?
答:使用 if-else
<1>if-else的使用格式
1 | if 条件: |
demo1
1 | chePiao = 1 # 用1代表有车票,0代表没有车票 |
结果1:有车票的情况
1 | 有车票,可以上火车 |
结果2:没有车票的情况
1 | 没有车票,不能上车 |
<2>练一练
1.要求:从键盘输入身高,如果身高没有超过150cm,则进动物园不用买票,否则需要买票。
2.要求:编写代码,1-7七个数字,分别代表周一到周日,如果输入的数字是6或7,输出“周末”,否则输出“工作日”。
2.5 elif
想一想:
if能完成当xxx时做事情
if-else能完成当xxx时做事情1,否则做事情2
如果有这样一种情况:当xxx1满足时做事情1;当xxx1不满足、xxx2满足时做事情2;当xxx2不满足、xxx3满足时做事情3,那该怎么实现呢?
答:
elif
<1> elif的功能
elif的使用格式如下:
1 | if xxx1: |
说明:
- 当xxx1满足时,执行事情1,然后整个if结束
- 当xxx1不满足时,那么判断xxx2,如果xxx2满足,则执行事情2,然后整个if结束
- 当xxx1不满足时,xxx2也不满足,如果xxx3满足,则执行事情3,然后整个if结束
demo:
1 | score = 77 |
<2> 注意点
可以和else一起使用 完整语法
1
2
3
4
5
6
7
8
9
10if 条件一成立:
执行语句...
elif 条件二成立:
执行语句...
elif 条件二成立:
执行语句...
elif 条件二成立:
执行语句...
else:
执行语句...说明:
elif必须和if一起使用,否则出错
else 一般用在最后,即所有条件都不满足时使用
练习
1 | 编写代码,1-7七个数字,分别代表周一到周日,如果输入的数字是6或7,输出“周末”,如果输入的数字是1-5,输 出“工作日”,如输入其他数字,输出“错误”。 |
1 | 小明身高1.75,体重80.5kg。请根据BMI公式(体重除以身高的平方)帮小明计算他的BMI指数, |
2.6 if嵌套
通过学习if的基本用法,已经知道了
- 当需要满足条件去做事情的这种情况需要使用if
- 当满足条件时做事情A,不满足条件做事情B的这种情况使用if-else
想一想:
坐火车或者地铁的实际情况是:先进行安检如果安检通过才会判断是否有车票,或者是先检查是否有车票之后才会进行安检,即实际的情况某个判断是再另外一个判断成立的基础上进行的,这样的情况该怎样解决呢?
答:
if嵌套
<1>if嵌套的格式
1 | if 条件1成立: |
- 说明 注意缩进
- 外层的if判断,也可以是if-else
- 内层的if判断,也可以是if-else
- 根据实际开发的情况,进行选择
<2>if嵌套的应用
demo:
1 | ticket = 1 # 用1代表有车票,0代表没有车票 |
结果1:ticket= 1;knife_lengh= 9
1 | 有车票,可以进站 |
结果2:ticket= 1;knife_lengh= 20
1 | 有车票,可以进站 |
结果3:ticket= 0;knife_lengh= 9
1 | 没有车票,不能进站 |
结果4:ticket= 0;knife_lengh= 20
1 | 没有车票,不能进站 |
- 想一想:为什么结果3和结果4相同???
<3>练一练
情节描述:上公交车去公园,并且可以有座位坐下
要求:输入公交卡当前的余额,只要超过2元,就可以上公交车,否则走着去;如果车上有空座位,就可以坐下,否则就站着吧。
2.7 应用:猜拳游戏
<1>运行效果:
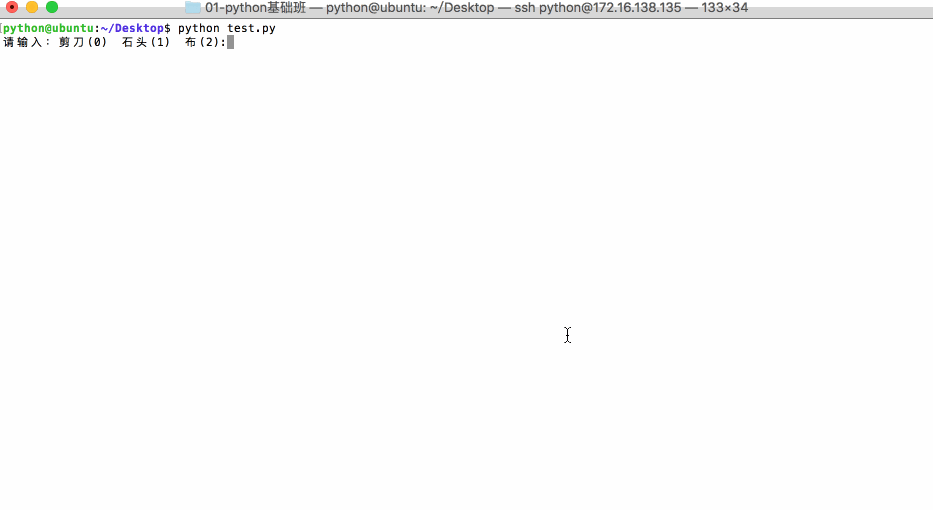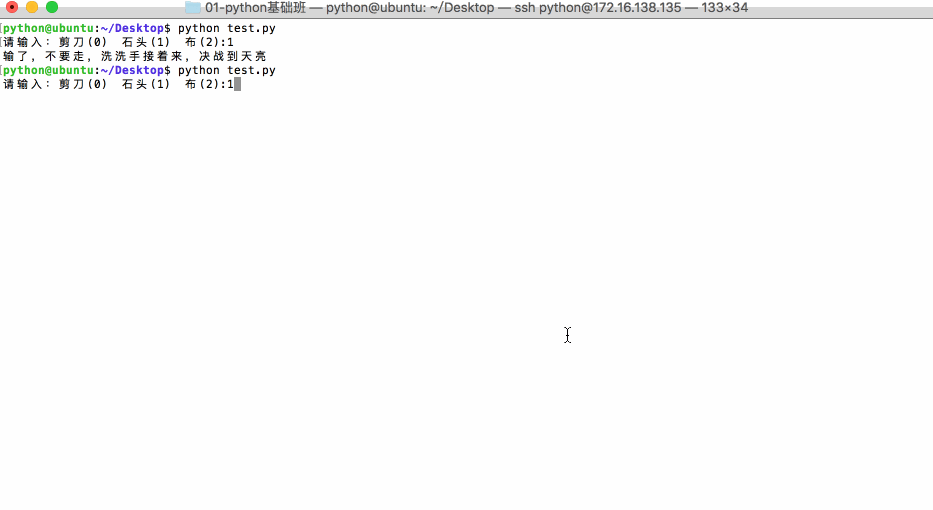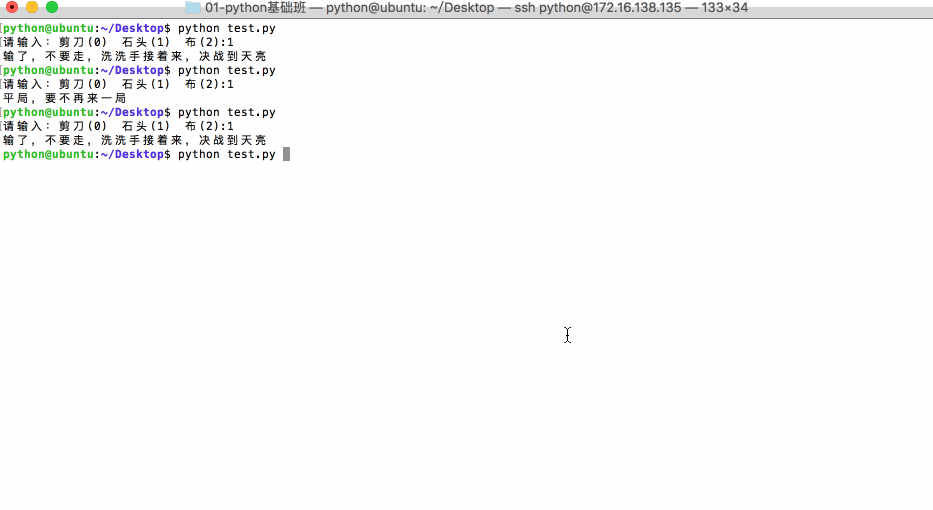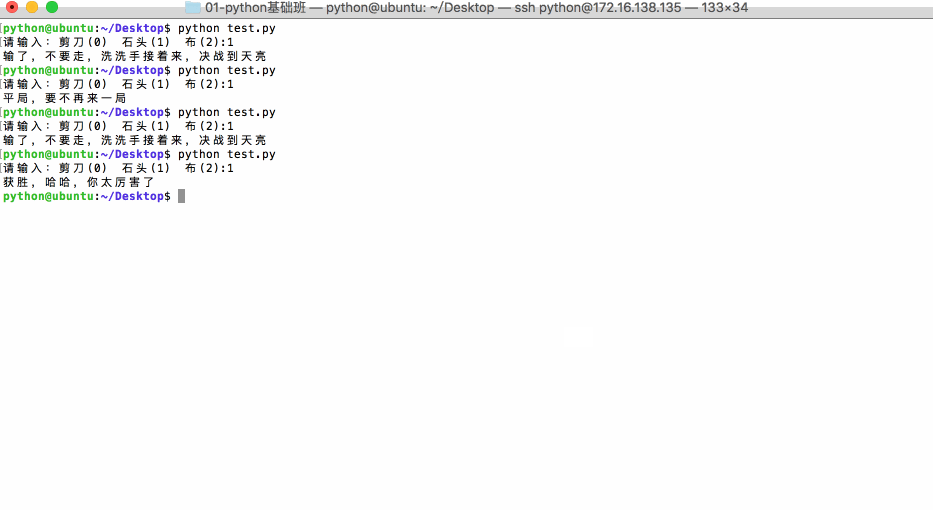
<2>参考代码:
1 | import random |
2.8 循环介绍
<1>生活中的循环场景
跑道

风扇

CF加特林
<2>软件开发中循环的使用场景
跟媳妇承认错误,说一万遍”媳妇儿,我错了”
1 | print("媳妇儿,我错了") |
使用循环语句一句话搞定
1 | i = 0 |
<3>小总结
- while和if的用法基本类似,区别在于:if 条件成立,则执行一次; while 条件成立,则重复执行,直到条件不成立为止。
- 一般情况下,需要多次重复执行的代码,都可以用循环的方式来完成
- 循环不是必须要使用的,但是为了提高代码的重复使用率,所以有经验的开发者都会采用循环
2.9 while循环
<1>while循环的格式
1 | while 条件: |
demo
1 | i = 0 |
结果:
1 | 当前是第1次执行循环 |
2.10 while循环应用
1. 计算1~100的累积和(包含1和100)
参考代码如下:
1 | #encoding=utf-8 |
2. 计算1~100之间偶数的累积和(包含1和100)
参考代码如下:
1 | #encoding=utf-8 |
2.11 while循环的嵌套以及应用(难)
- 前面学习过if的嵌套了,想一想if嵌套是什么样子的?
- 类似if的嵌套,while嵌套就是:while里面还有while
<1>while嵌套的格式
1 | while 条件1: |
<2>while嵌套应用一
要求:打印如下图形:
1 | * |
参考代码:
1 | i = 1 |
<3>while嵌套应用二:九九乘法表
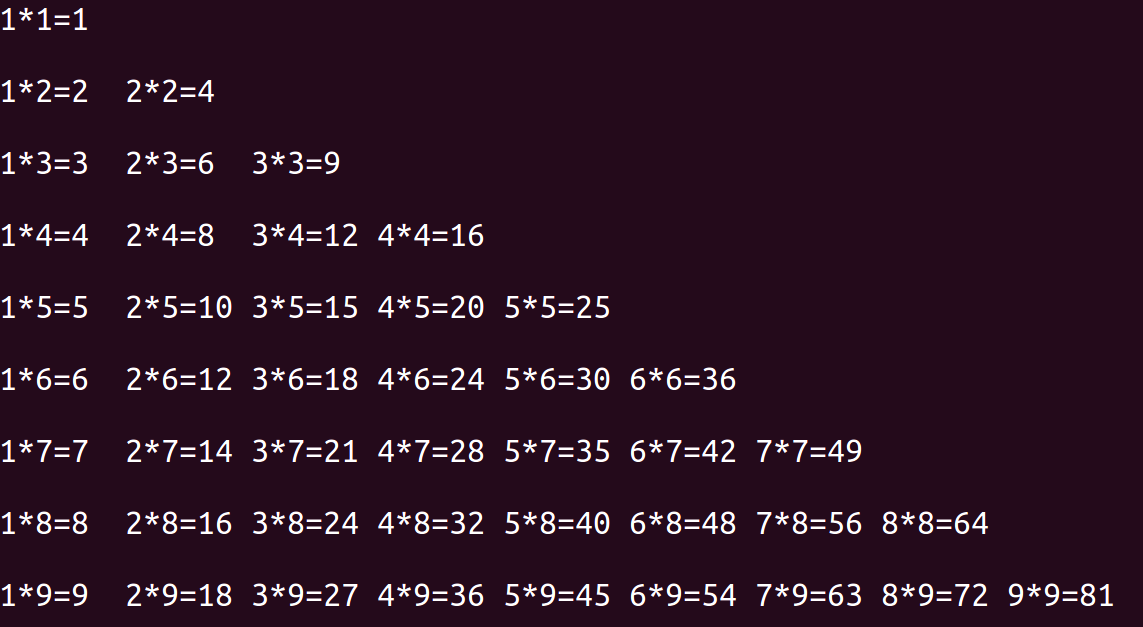
参考代码:
1 | i = 1 |
2.12 for循环
像while循环一样,for可以完成循环的功能。
在Python中 for循环可以遍历任何序列的项目,如一个列表或者一个字符串等。
for循环的格式
1 | for 临时变量 in 列表或者字符串等可迭代对象: |
demo1
1 | name = 'itheima' |
运行结果如下:
1 | i |
demo2
1 | for x in name: |
运行结果如下:
1 | h |
demo3
1 | # range(5) 在python就业班中进行讲解会牵扯到迭代器的知识, |
运行结果如下:
1 | 0 |
2.13 break和continue
1. break
while循环
- 普通的循环示例如下:
1 | i = 0 |
运行结果:
1 | ---- |
- 带有break的循环示例如下:
1 | i = 0 |
运行结果:
1 | ---- |
小结:
- break的作用:立刻结束break所在的循环
2. continue
while循环
- 带有continue的循环示例如下:
1 | i = 0 |
运行结果:
1 | ---- |
小结:
- continue的作用:用来结束本次循环,紧接着执行下一次的循环,相当于跳过了当前这次循环
3. 注意点
- break/continue只能用在循环中,除此以外不能单独使用
- break/continue在嵌套循环中,只对最近的一层循环起作用
3.1 字符串介绍
<1>python中字符串的格式
如下定义的变量a,存储的是数字类型的值
1 | a = 100 |
如下定义的变量b,存储的是字符串类型的值
1 | b = "hello itcast.cn" |
小总结:
- 双引号或者单引号中的数据,就是字符串
3.2 字符串输出
demo
1 | name = 'czxy' |
结果:
1 | -------------------------------------------------- |
3.3 字符串输入
之前在学习input的时候,通过它能够完成从键盘获取数据,然后保存到指定的变量中;
注意:input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
demo:
1 | userName = input('请输入用户名:') |
结果:(根据输入的不同结果也不同)
1 | 请输入用户名:czxy |
3.4 下标和切片
1. 下标索引
所谓“下标”,就是编号,就好比超市中的存储柜的编号,通过这个编号就能找到相应的存储空间
生活中的 “下标”
超市储物柜

高铁二等座

高铁一等座

绿皮车

字符串中”下标”的使用
列表与元组支持下标索引好理解,字符串实际上就是字符的数组,所以也支持下标索引。
如果有字符串:
name = 'abcdef',在内存中的实际存储如下: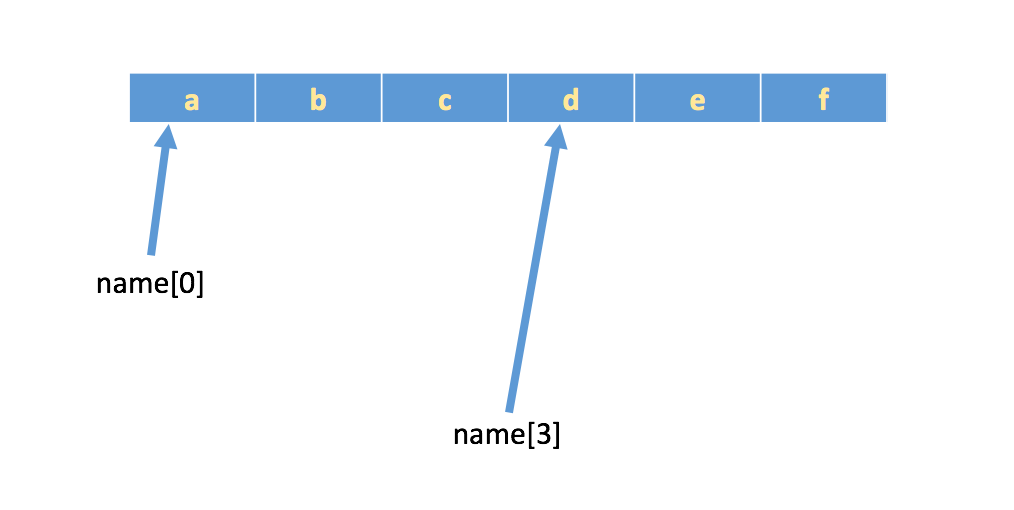
如果想取出部分字符,那么可以通过
下标的方法,(注意python中下标从 0 开始)1
2
3
4
5name = 'abcdef'
print(name[0])
print(name[1])
print(name[2])运行结果:
1
2
3a
b
c
2. 切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长]
注意:选取的区间从”起始”位开始,到”结束”位的前一位结束(不包含结束位本身),步长表示选取间隔。
我们以字符串为例讲解。
如果取出一部分,则可以在中括号[]中,使用:
1 | name = 'abcdef' |
运行结果:

1 | name = 'abcdef' |
运行结果: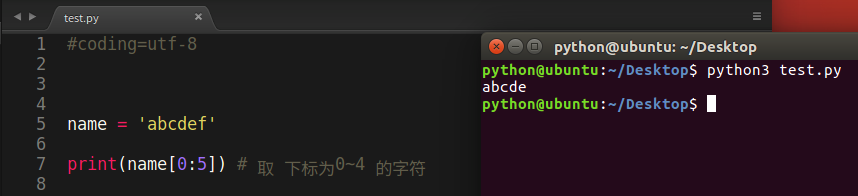
1 | name = 'abcdef' |
运行结果:
1 | name = 'abcdef' |
运行结果:
1 | name = 'abcdef' |
运行结果:
1 | a = 'abcdef' |
想一想
- (面试题)给定一个字符串aStr, 请反转字符串
1 | # 索引是通过下标取某一个元素 |
3.5 字符串常见操作
如有字符串mystr = 'hello world itcast and itcastcpp',以下是常见的操作
<1>find
检测 str 是否包含在 mystr中,如果是返回开始的索引值,否则返回-1
1 | mystr.find(str, start=0, end=len(mystr)) # 方法介绍 |
<2>index
跟find()方法一样,只不过如果str不在 mystr中会报一个异常.
1 | mystr.index(str, start=0, end=len(mystr)) |

<3>count
返回 str在start和end之间 在 mystr里面出现的次数
1 | mystr.count(str, start=0, end=len(mystr)) |
<4>replace
把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
1 | mystr.replace(str1, str2, count) |
<5>split
以 seq为分隔符对字符串mystr分隔,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串, 最后的结果存放到列表里
1 | mystr.split(seq, maxsplit) |
如果split不指定分隔符,那么默认就是用空格分隔,如下
1 | str01 = 'hello ha ha he he world\t python' |
注意如果分隔符在字符串左侧或者右侧,结果会多出空字符串,效果如下
1 | str01 = 'hello ha ha he he' |
可以指定分隔的次数 如下
1 | str01 = '2018-01-02-03-04' |
<6>capitalize
把字符串的第一个字符大写
1 | mystr.capitalize() |
<7>title
把字符串的每个单词首字母大写
1 | str01 = 'hello python ha ha' |
<8>startswith
检查字符串是否是以 hello 开头, 是则返回 True,否则返回 False
1 | str01 = 'hello python ha ha' |
<9>endswith
检查字符串是否以obj结束,如果是返回True,否则返回 False.
1 | str01 = 'hello python ha ha' |
<10>lower
转换 mystr 中所有大写字符为小写
1 | str01 = 'HELLO python ha ha' |
<11>upper
转换 mystr 中的小写字母为大写
1 | str01 = 'HELLO python ha ha' |
<12>ljust
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
1 | mystr.ljust(width) |
<13>rjust
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
1 | mystr.rjust(width) |
<14>center
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
1 | mystr.center(width) |
<15>lstrip
删除 mystr 左边的空白字符
1 | mystr.lstrip() |
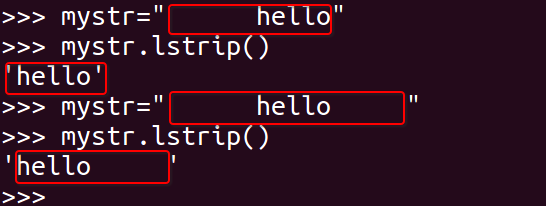
<16>rstrip
删除 mystr 字符串末尾的空白字符
1 | mystr.rstrip() |
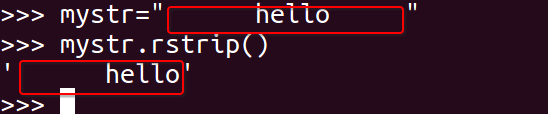
<17>strip
删除mystr字符串两端的空白字符
1 | mystr.strip() |

<18>rfind
类似于 find()函数,不过是从右边开始查找.
1 | mystr.rfind(str, start=0,end=len(mystr) ) |
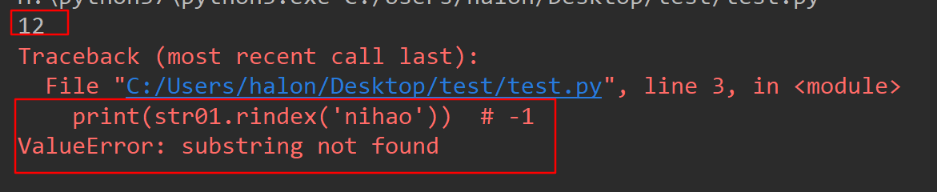
<19>rindex
类似于 index(),不过是从右边开始.
1 | mystr.rindex( str, start=0,end=len(mystr)) |
<20>partition
把mystr以str分割成三部分,str前,str和str后
1 | mystr.partition(str) |
<21>rpartition
类似于 partition()函数,不过是从右边开始.
1 | mystr.rpartition(str) |
<22>splitlines
按照行分隔,返回一个包含各行作为元素的列表
1 | mystr.splitlines() |
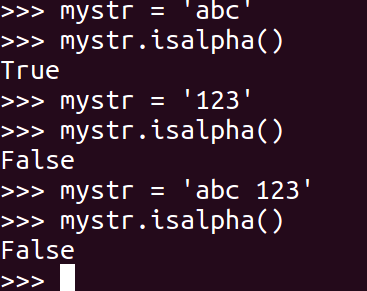
<23>isalpha
如果 mystr 所有字符都是字母 则返回 True,否则返回 False
1 | mystr.isalpha() |
<24>isdigit
如果 mystr 只包含数字则返回 True 否则返回 False.
1 | mystr.isdigit() |
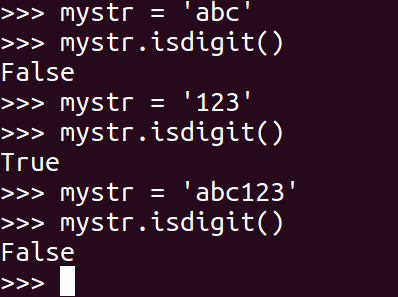
<25>isalnum
如果 mystr 所有字符都是字母或数字则返回 True,否则返回 False
1 | mystr.isalnum() |
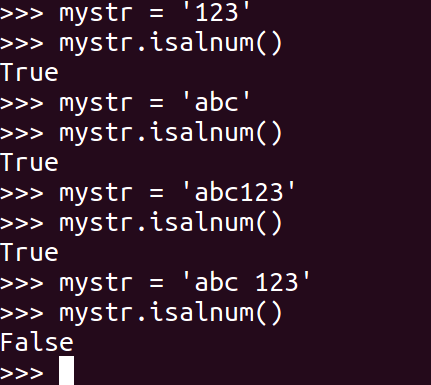
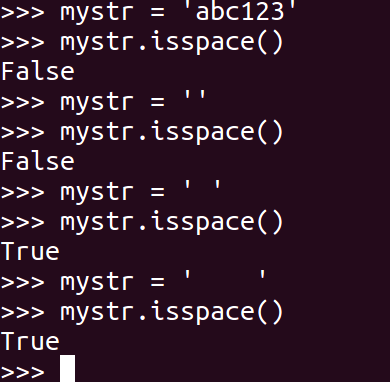
<26>isspace
如果 mystr 中只包含空格,则返回 True,否则返回 False.
1 | mystr.isspace() |
<27>join
mystr 中每个元素后面插入str,构造出一个新的字符串
1 | mystr.join() |
想一想
- (面试题)给定一个字符串aStr,返回使用空格或者’\t’分割后的倒数第二个子串

3.6 列表介绍
想一想:
前面学习的字符串可以用来存储一串信息,那么想一想,怎样存储咱们班所有同学的名字呢?
定义100个变量,每个变量存放一个学生的姓名可行吗?有更好的办法吗?
答:
列表
<1>列表的格式
变量A的类型为列表
1 | namesList = ['xiaoWang','xiaoZhang','xiaoHua'] |
比C语言的数组强大的地方在于列表中的元素可以是不同类型的
1 | testList = [1, 'a'] |
<2>打印列表
demo:
1 | namesList = ['xiaoWang','xiaoZhang','xiaoHua'] |
结果:
1 | xiaoWang |
3.7 列表的循环遍历
1. 使用for循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
demo:
1 | names = ["张三", "李四", "王六", 'halon', '小马哥'] |
结果:
1 | 张三 |
2. 使用while循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
demo:
1 | names = ["张三", "李四", "王六", 'halon', '小马哥'] |
结果:
1 | 张三 |
3.8 列表的相关操作
列表中存放的数据是可以进行修改的,比如”增”、”删”、”改””
<1>添加元素(“增”append, extend, insert)
append
通过append可以向列表添加元素
demo:
1 | # 定义列表names 有三个元素 |
结果:

extend
通过extend可以将另一个集合中的元素逐一添加到列表中
1 | list01 = [1, 2] |
效果

insert
insert(index, object) 在指定位置index前插入元素object
1 | list01 = [0, 1, 2, 3, 4] |
<2>修改元素(“改”)
修改元素的时候,要通过下标来确定要修改的是哪个元素,然后才能进行修改
demo:
1 | #定义变量A,默认有3个元素 |
结果:
1 | -----修改之前,列表A的数据----- |
<3>查找元素(“查”in, not in, index, count)
所谓的查找,就是看看指定的元素是否存在
in, not in
python中查找的常用方法为:
- in(存在),如果存在那么结果为true,否则为false
- not in(不存在),如果不存在那么结果为true,否则false
demo
1 | #待查找的列表 |
结果1:(找到)

结果2:(没有找到)

说明:
in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在
index, count
index和count与字符串中的用法相同
1 | a = ['a', 'b', 'c', 'a', 'b'] |
<4>删除元素(“删”del, pop, remove)
类比现实生活中,如果某位同学调班了,那么就应该把这个条走后的学生的姓名删除掉;在开发中经常会用到删除这种功能。
列表元素的常用删除方法有:
- del:根据下标进行删除
- pop:删除最后一个元素
- remove:根据元素的值进行删除
demo:(del)
1 | movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] |
结果:
1 | ------删除之前------ |
demo:(pop)
1 | movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] |
结果:
1 | ------删除之前------ |
demo:(remove)
1 | movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] |
结果:
1 | ------删除之前------ |
<5>排序(sort, reverse)
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
reverse方法是将list逆置。
1 | a = [1, 4, 2, 3] |
3.9 列表的嵌套
1. 列表嵌套
类似while循环的嵌套,列表也是支持嵌套的
一个列表中的元素又是一个列表,那么这就是列表的嵌套
1 | schoolNames = [['北京大学','清华大学'], |
2. 应用
一个学校,有3个办公室,现在有8位老师等待工位的分配,请编写程序,完成随机的分配
1 | #encoding=utf-8 |
运行结果如下:

3.10 元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
1 | aTuple = ('et',77,99.9) |
<1>访问元组
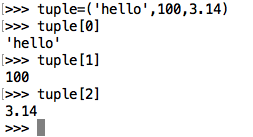
<2>修改元组

说明: python中不允许修改元组的数据,包括不能删除其中的元素。
<3>count, index
index和count与字符串和列表中的用法相同
1 | a = ('a', 'b', 'c', 'a', 'b') |
3.11 字典介绍
想一想:
如果有列表
1 | nameList = ['xiaoZhang', 'xiaoWang', 'xiaoLi']; |
需要对”xiaoWang”这个名字写错了,通过代码修改:
1 | nameList[1] = 'xiaoxiaoWang' |
如果列表的顺序发生了变化,如下
1 | nameList = ['xiaoWang', 'xiaoZhang', 'xiaoLi']; |
此时就需要修改下标,才能完成名字的修改
1 | nameList[0] = 'xiaoxiaoWang' |
有没有方法,既能存储多个数据,还能在访问元素的很方便就能够定位到需要的那个元素呢?
答:
字典
另一个场景:
学生信息列表,每个学生信息包括学号、姓名、年龄等,如何从中找到某个学生的信息?
1 | studens = [[1001, "王bao强", 24], [1002, "马rong", 23], [1005, "宋x",24], ...] |
循环遍历? No!
<1>生活中的字典


<2>软件开发中的字典
变量info为字典类型:
1 | info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'} |
说明:
- 字典和列表一样,也能够存储多个数据
- 列表中找某个元素时,是根据下标进行的
- 字典中找某个元素时,是根据’名字’(就是冒号:前面的那个值,例如上面代码中的’name’、’id’、’sex’)
- 字典的每个元素由2部分组成,键:值。例如 ‘name’:’班长’ ,’name’为键,’班长’为值
<3>根据键访问值
1 | info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'} |
结果:
1 | 班长 |
若访问不存在的键,则会报错:
1 | info['age'] |
在我们不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值:
1 | age = info.get('age') |
3.12 字典的常见操作1
<1>修改元素
字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改
demo:
1 | info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'} |
结果:

<2>添加元素
demo: 访问不存在的元素
1 | info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'} |
结果:
1 | info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'} |
如果在使用 变量名['键'] = 数据 时,这个“键”在字典中,不存在,那么就会新增这个元素。
demo: 添加新的元素
1 | info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'} |
结果:
1 | 请输入新的学号:188 |
<3>删除元素
对字典进行删除操作,有一下几种:
- del
- clear()
demo: del删除指定的元素
1 | info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'} |
结果
1 | info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'} |
demo: del删除整个字典
1 | info = {'name':'monitor', 'sex':'f', 'address':'China'} |
结果

demo: clear清空整个字典
1 | info = {'name':'monitor', 'sex':'f', 'address':'China'} |
结果

3.13 字典的常见操作2
<1>len()
测量字典中,键值对的个数
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
<2>keys
返回一个包含字典所有KEY的列表
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
<3>values
返回一个包含字典所有value的列表
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
<4>items
返回一个包含所有(键,值)元祖的列表
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
<5>has_key (Python3 已取消,了解即可)
dict.has_key(key)如果key在字典中,返回True,否则返回False,注意用python2运行
1 | # -*- coding:utf-8 -*— |
3.14 字典的遍历
通过for … in … 我们可以遍历字符串、列表、元组、字典等
注意python语法的缩进
字符串遍历
1 | a_str = "hello itcast" |
列表遍历
1 | a_list = [1, 2, 3, 4, 5] |
元组遍历
1 | a_turple = (1, 2, 3, 4, 5) |
字典遍历
<1> 遍历字典的key(键)
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
<2> 遍历字典的value(值)
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
<3> 遍历字典的项(元素)
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
<4> 遍历字典的key-value(键值对)
1 | dict01 = {'name': '张三', 'age': 18, 'sex': 'm'} |
想一想,如何实现带下标索引的遍历
1 | chars = ['a', 'b', 'c', 'd'] |
enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
1 | chars = ['a', 'b', 'c', 'd'] |
3.15 公共方法
运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 复制 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
+
1 | "hello " + "itcast" |
*
1 | 'ab' * 4 |
in
1 | 'itc' in 'hello itcast' |
注意,in在对字典操作时,判断的是字典的键
python内置函数
Python包含了以下内置函数
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | cmp(item1, item2) | 比较两个值 |
| 2 | len(item) | 计算容器中元素个数 |
| 3 | max(item) | 返回容器中元素最大值 |
| 4 | min(item) | 返回容器中元素最小值 |
| 5 | del(item) | 删除变量 |
cmp
1 | cmp("hello", "itcast") |
注意:cmp在比较字典数据时,先比较键,再比较值。
len
1 | len("hello itcast") |
注意:len在操作字典数据时,返回的是键值对个数。
max
1 | max("hello itcast") |
del
del有两种用法,一种是del加空格,另一种是del()
1 | a = 1 |
多维列表/元祖访问的示例
1 | tuple1 = [(2,3),(4,5)] |
4.1 函数介绍
<1>什么是函数
请看如下代码:
1 | str01 = input('输入你的行为') |
想一想:
如果还有其他违纪行为,比如宿舍卫生不打扫,惩罚的代码是不是还要重复再写一遍,
小总结:
- 如果在开发程序时,需要某块代码多次,但是为了提高编写的效率以及代码的重用,所以把具有独立功能的代码块组织为一个小模块,这就是函数
4.2 函数定义和调用
<1>定义函数
定义函数的格式如下:
1 | def 函数名(): |
demo:
1 | # 定义一个函数,能够完成打印信息的功能 |
<2>调用函数
定义了函数之后,就相当于有了一个具有某些功能的代码,想要让这些代码能够执行,需要调用它
调用函数很简单的,通过 函数名() 即可完成调用
demo:
1 | # 定义完函数后,函数是不会自动执行的,需要调用它才可以 |
<3>注意:
- 每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了
- 当然了如果函数中执行到了return也会结束函数
<4>练一练
要求:定义一个函数,能够输出自己的姓名和年龄,并且调用这个函数让它执行
- 使用def定义函数
- 编写完函数之后,通过 函数名() 进行调用
4.3 函数的文档说明
1 | def sum_2_num(a, b): |
如果执行,以下代码
1 | help(sum_2_num) |
能够看到test函数的相关说明
1 | Help on function test in module __main__: |
用快捷键 ctrl+q或者ctrl+shift+i 也可以查看函数介绍
4.4 函数参数(一)
思考一个问题,如下:
现在需要定义一个函数,这个函数能够完成2个数的加法运算,并且把结果打印出来,该怎样设计?下面的代码可以吗?有什么缺陷吗?
2
3
4
5
a = 11
b = 22
c = a+b
print c
为了让一个函数更通用,即想让它计算哪两个数的和,就让它计算哪两个数的和,在定义函数的时候可以让函数接收数据,就解决了这个问题,这就是 函数的参数
<1> 定义带有参数的函数
示例如下:
1 | def add2num(a, b): |
<2> 调用带有参数的函数
以调用上面的add2num(a, b)函数为例:
1 | def add2num(a, b): |
调用带有参数函数的运行过程:

<3> 练一练
要求:定义一个函数,完成前2个数完成加法运算,然后对第3个数,进行减法;然后调用这个函数
- 使用def定义函数,要注意有3个参数
- 调用的时候,这个函数定义时有几个参数,那么就需要传递几个参数
<4> 调用函数时参数的顺序
1 | def test(a,b): |
<4> 小总结
- 定义时小括号中的参数,用来接收参数用的,称为 “形参”
- 调用时小括号中的参数,用来传递给函数用的,称为 “实参”
4.5 函数返回值(一)
<1>“返回值”介绍
现实生活中的场景:
你拿个锤子,我把核桃给你,核桃相当于我传给你的参数,最后我的目的是要你砸好的核桃仁,核桃仁就是返回值
开发中的场景:
定义了一个函数,完成了获取室内温度,想一想是不是应该把这个结果给调用者,只有调用者拥有了这个返回值,才能够根据当前的温度做适当的调整
综上所述:
- 所谓“返回值”,就是程序中函数完成一件事情后,最后给调用者的结果
<2>带有返回值的函数
想要在函数中把结果返回给调用者,需要在函数中使用return
如下示例:
1 | def add2num(a, b): |
<3>保存函数的返回值
你把核桃仁给我了,我就要存起来,然后在自己处理
保存函数的返回值示例如下:
1 | #定义函数 |
结果:
1 | 198 |
4.6 4种函数的类型
函数根据有没有参数,有没有返回值,可以相互组合,一共有4种
- 无参数,无返回值
- 无参数,有返回值
- 有参数,无返回值
- 有参数,有返回值
<1>无参数,无返回值的函数
此类函数,不能接收参数,也没有返回值,一般情况下,打印提示灯类似的功能,使用这类的函数
1 | def printMenu(): |
结果:

<2>无参数,有返回值的函数
此类函数,不能接收参数,但是可以返回某个数据,一般情况下,像采集数据,用此类函数
1 | # 获取温度 |
结果:
1 | 当前的温度为: 24 |
<3>有参数,无返回值的函数
此类函数,能接收参数,但不可以返回数据,一般情况下,对某些变量设置数据而不需结果时,用此类函数,一般很少使用,需求不多
<4>有参数,有返回值的函数
此类函数,不仅能接收参数,还可以返回某个数据,一般情况下,像数据处理并需要结果的应用,用此类函数
1 | # 计算1~num的累积和 |
结果:
1 | 1~100的累积和为: 5050 |
<5>小总结
- 函数根据有没有参数,有没有返回值可以相互组合
- 定义函数时,是根据实际的功能需求来设计的,所以不同开发人员编写的函数类型各不相同
4.7 函数的嵌套调用
1 | def testB(): |
结果:
1 | ---- testA start---- |
小总结:
- 一个函数里面又调用了另外一个函数,这就是所谓的函数嵌套调用

- 如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
4.8 函数应用:打印图形和数学计算
目标
- 感受函数的嵌套调用
- 感受程序设计的思路,复杂问题分解为简单问题
思考&实现1
- 写一个函数打印一条横线
- 打印自定义行数的横线
参考代码1
1 | # 打印一条横线 |
思考&实现2
- 写一个函数求三个数的和
- 写一个函数求三个数的平均值
参考代码2
1 | # 求3个数的和 |
5.0 函数(二)
5.1 局部变量
<1>什么是局部变量
如下图所示:
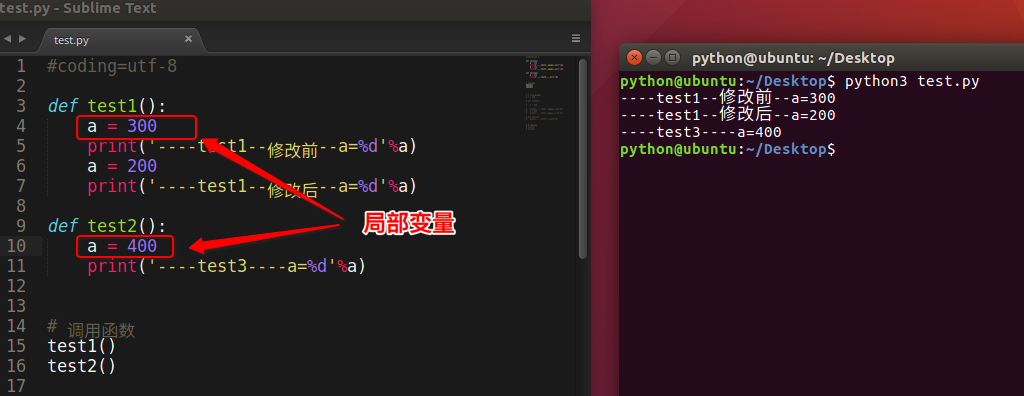
<2>小总结
- 局部变量,就是在函数内部定义的变量
- 其作用范围是这个函数内部,即只能在这个函数中使用,在函数的外部是不能使用的
- 因为其作用范围只是在自己的函数内部,所以不同的函数可以定义相同名字的局部变量(打个比方,把你、我是当做成函数,把局部变量理解为每个人手里的手机,你可有个iPhone8,我当然也可以有个iPhone8了, 互不相关)
- 局部变量的作用,为了临时保存数据需要在函数中定义变量来进行存储
- 当函数调用时,局部变量被创建,当函数调用完成后这个变量就不能够使用了
5.2 全局变量
<1>什么是全局变量
如果一个变量,既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量
打个比方:有2个兄弟 各自都有手机,各自有自己的小秘密在手机里,不让另外一方使用(可以理解为局部变量);但是家里的电话是2个兄弟都可以随便使用的(可以理解为全局变量)
demo如下:
1 | # 定义全局变量 |
运行结果:

总结1:
- 在函数外边定义的变量叫做
全局变量 - 全局变量能够在所有的函数中进行访问
<2>全局变量和局部变量名字相同问题
看如下代码:
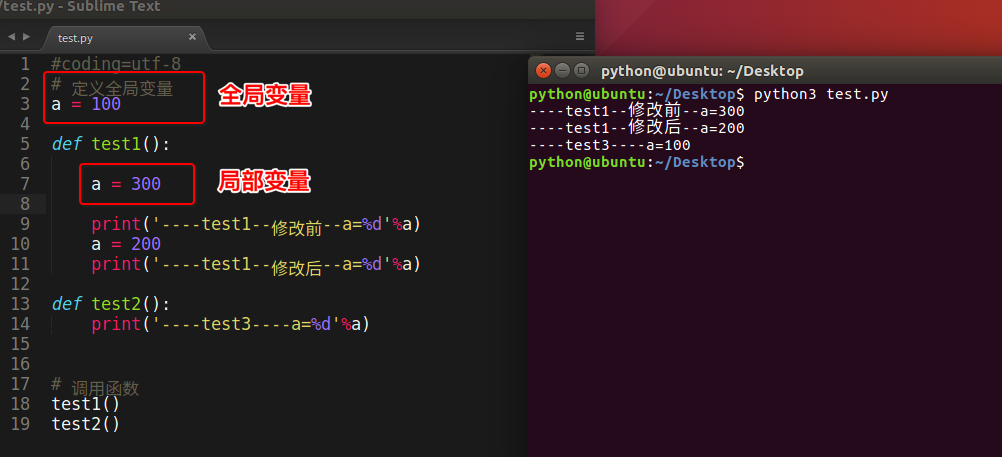
总结2:
- 当函数内出现局部变量和全局变量相同名字时,函数内部中的
变量名 = 数据此时理解为定义了一个局部变量,而不是修改全局变量的值
<3>修改全局变量
函数中进行使用时可否进行修改呢?
代码如下:
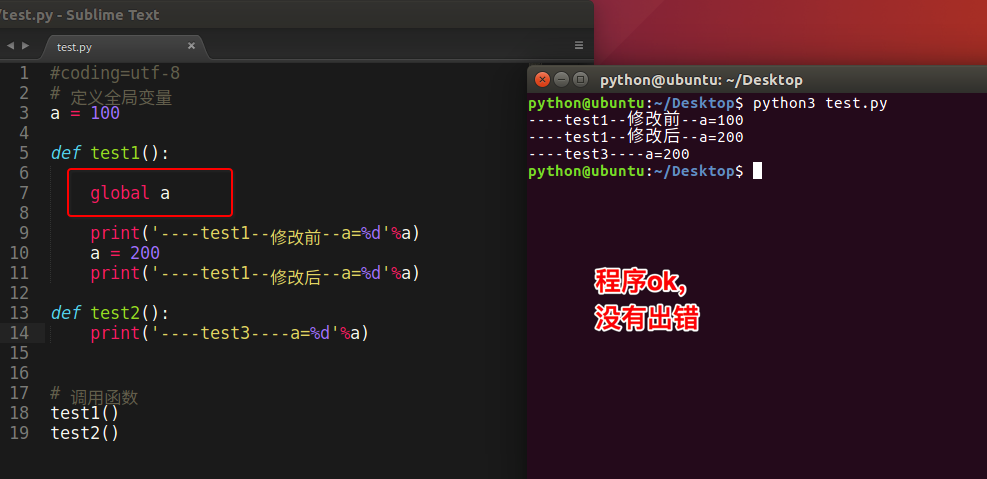
总结3:
如果在函数中出现
global 全局变量的名字那么这个函数中即使出现和全局变量名相同的变量名 = 数据也理解为对全局变量进行修改,而不是定义局部变量如果在一个函数中需要对多个全局变量进行修改,那么可以使用
1
2
3
4
5# 可以使用一次global对多个全局变量进行声明
global a, b
# 还可以用多次global声明都是可以的
# global a
# global b
5.3 多函数程序的基本使用流程
一般在实际开发过程中,一个程序往往由多个函数(后面知识中会讲解类)组成,并且多个函数共享某些数据,这种场景是经常出现的,因此下面来总结下,多个函数中共享数据的几种方式
1. 使用全局变量
1 | g_num = 0 |
2. 使用函数的返回值、参数
1 | def test1(): |
3. 函数嵌套调用
1 | def test1(): |
5.4 函数返回值(二)
在python中我们怎样返回多个值?
<1> 多个return?
1 | def create_nums(): |
总结1:
一个函数中可以有多个return语句,但是只要有一个return语句被执行到,那么这个函数就会结束了,因此后面的return没有什么用处
如果程序设计为如下,是可以的因为不同的场景下执行不同的return
1
2
3
4
5
6
7
8
9
10
11
12
13
14def create_nums(num):
print("---1---")
if num == 100:
print("---2---")
return num+1 # 函数中下面的代码不会被执行,因为return除了能够将数据返回之外,还有一个隐藏的功能:结束函数
else:
print("---3---")
return num+2
print("---4---")
result1 = create_nums(100)
print(result1) # 打印101
result2 = create_nums(200)
print(result2) # 打印202
<2> 一个函数返回多个数据的方式
return后面可以是元组,列表、字典等,只要是能够存储多个数据的类型,就可以一次性返回多个数据
如果return后面有多个数据,那么默认是元组
1 | def calc_2_num(a, b): |
多个数据逗号分隔,默认是元组
1
2m = 1, 2, 3
print(m) # (1, 2, 3)
5.5 函数参数(二)
位置参数(positional argument)
1
2
3
4
5
6
7
8def print_info(name, age):
# 打印任何传入的字符串
print("name: %s" % name)
print("age %d" % age)
# 调用print_info函数
print_info("halon",18)
print_info("mayun", 48) # 参数按照从左向右的位置依次传入,叫位置参数- 可以通过指定参数名字的方式进行传值
``` def print_info(name, age):
1
2
3# 打印任何传入的字符串
print("name: %s" % name)
print("age %d" % age)
调用print_info函数
print_info(age = 48, name=’yanhong’) # 指定参数名字的方式进行传值
1 |
|
以上实例输出结果:
1 | name: halon |
总结:
在形参中默认有值的参数,称之为缺省参数
注意:缺省参数一定要位于位置参数的后面
1 | def print_info(age=18,name): |
有时可能需要一个函数能处理比当初声明时更多的参数, 这些参数叫做不定长参数,声明时不会命名。
基本语法如下:
1 | def functionname([formal_args,] *args): |
注意:
- 加了星号(*)的变量args会存放所有未命名的变量参数,args为元组
1 | def sum_nums(a, b, c=0, *args): |
缺省参数在*args后面
1 | def sum_nums_3(a, *args, b=22, c=33): |
1 | def sum_nums(a, b=11, c=22, *args, **kwargs): |
5.6 拆包、交换变量的值
<1> 对返回的数据直接拆包
1 | def get_my_info(): |
总结:
拆包时要注意,需要拆的数据的个数要与变量的个数相同,否则程序会异常
除了对元组拆包之外,还可以对列表、字典等拆包
1
2
3
4
5
6
7
8
9
10
11
12# a, b = (11, 22)
a, b = 11, 22
print(a)
print(b)
a, b = [11, 22]
print(a)
print(b)
a, b = {"m": 11, "n": 22} # 取出来的是key,而不是键值对
print(a) #m
print(b) #n
<2> 交换2个变量的值
1 | # 第1种方式 |
5.7 引用(一)
存放的地址

数据在内存中存储的地址
我们之前讲过程序在运行时,代码数据先要放到内存里
数据在内存里肯定不能乱放,cpu需要找到数据运算,就需要有个地址,就像大家住在宿舍是不是也要有个门牌号,小明住在3号宿舍楼605 。那数据也是一样的 有地址
那我想看一下 这些数据地址是什么样子? 用函数id()
1 | a = 100 # 我想看看这个100存到哪呢 门牌号是几? 用一个函数 id() |
以上代码打印的那些很长的数字 就是数据在内存的地址
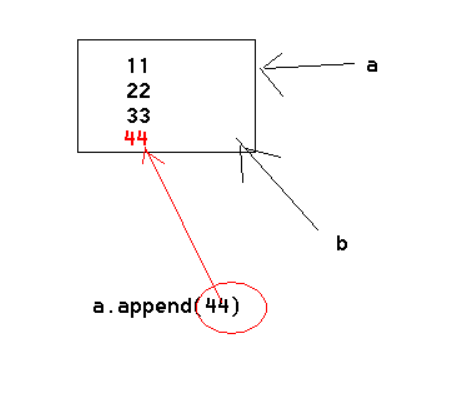
数据在内存中的样子,如图:

在python中,值是靠引用来传递来的
如上图,变量a和b 就是一个引用 这个引用存的是数据的地址 ,
通过地址可以找到这个数据,就像我通过一个号门牌号找到张三一样
看下面代码,想一想a和b相等吗?id(a)和id(b)呢?
1 | a = [11,22,33] |
发现a和b相同 id(a)和id(b)也相同

以后再遇到 变量=值的情况 比如
a = 100 变量a是100的引用,存的是数据100地址
1 | a = 1 |
总结:
- 之前为了更好的理解变量,咱们可以把
a=100理解为变量a中存放了100,事实上变量a存储是100的引用(可理解为在内存中的一个编号)
5.8 可变、不可变类型
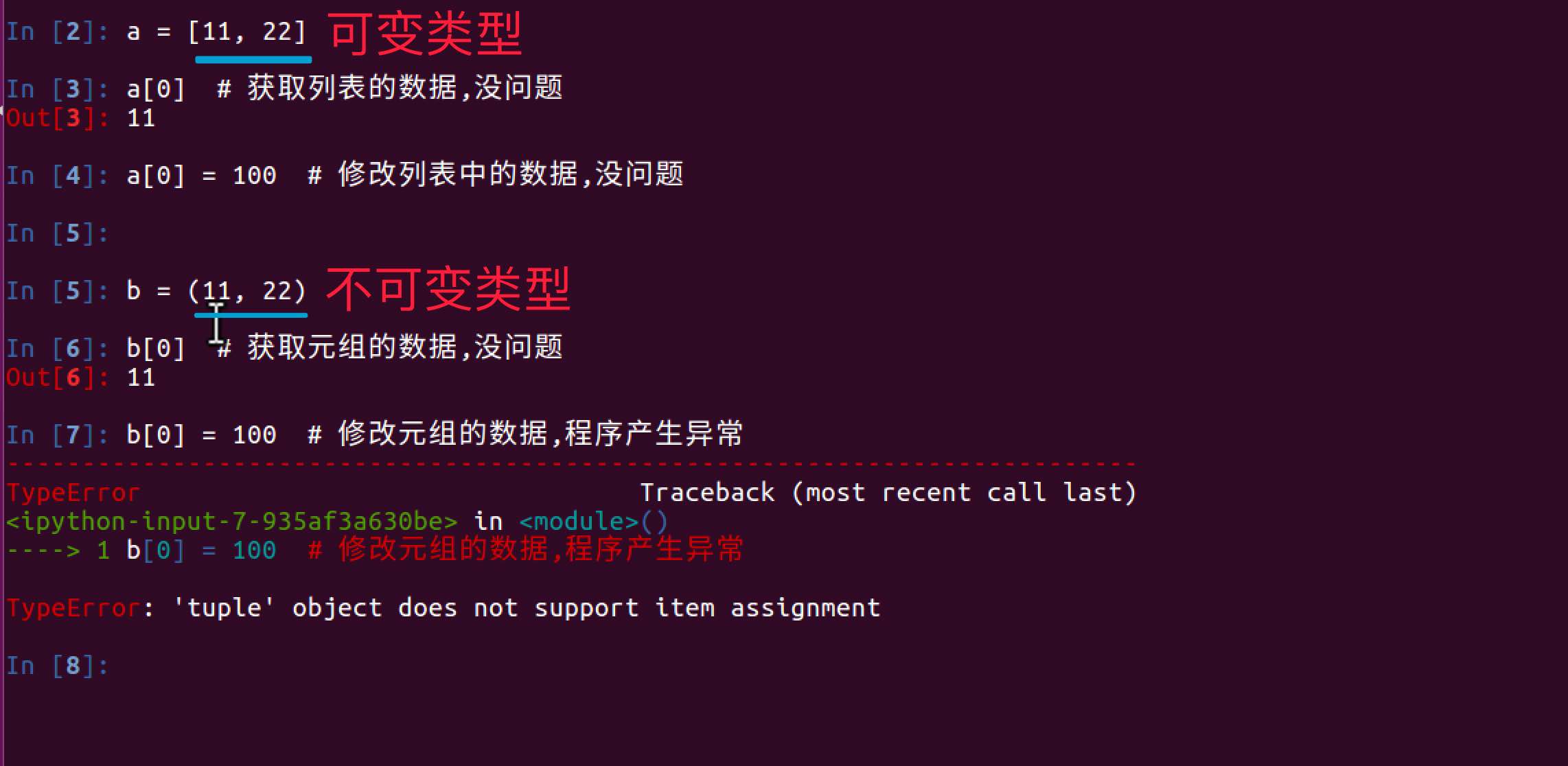
总结
- 所谓可变类型与不可变类型是指:数据能够直接进行修改,如果能直接修改那么就是可变,否则是不可变
- 可变类型有: 列表、字典、集合
- 不可变类型有: 数字、字符串、元组
5.9 引用(二)
引用当做实参
- Python中函数参数是引用传递
- 可变类型与不可变类型的变量分别作为函数参数时,会有什么不同吗?
1 | def test1(b): # 变量b一定是一个局部变量,就看它指向的是谁?可变还是不可变 |
总结:
- Python中函数参数是引用传递(注意不是值传递)
- 对于不可变类型,因变量不能修改,所以运算不会影响到变量自身
- 而对于可变类型来说,函数体中的运算有可能会更改传入的参数变量
5.10 函数使用注意事项
1. 自定义函数
无参数、无返回值
1 | def 函数名(): |
无参数、有返回值
1 | def 函数名(): |
注意:
- 一个函数到底有没有返回值,就看有没有return,因为只有return才可以返回数据
- 在开发中往往根据需求来设计函数需不需要返回值
- 函数中,可以有多个return语句,但是只要执行到一个return语句,那么就意味着这个函数的调用完成
有参数、无返回值
1 | def 函数名(形参列表): |
注意:
- 在调用函数时,如果需要把一些数据一起传递过去,被调用函数就需要用参数来接收
- 参数列表中变量的个数根据实际传递的数据的多少来确定
有参数、有返回值
1 | def 函数名(形参列表): |
函数名不能重复
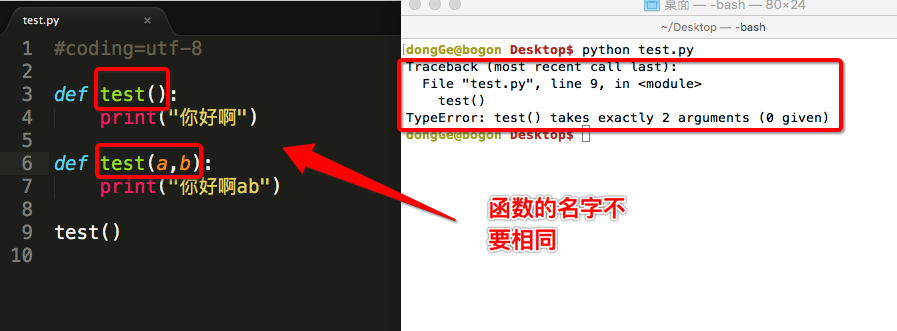
- 如果在同一个程序中出现了多个相同函数名的函数,那么在调用函数时就会出现问题,所以要避免名字相同
- 还有一点 不仅要避免函数名之间不能相同,还要避免 变量名和函数名相同的,否则都会出现问题
- 详细的讲解在后面python高级知识中进行学习,此阶段只要注意这些问题即可
2. 调用函数
调用的方式为:
1 | 函数名([实参列表]) |
调用时,到底写不写 实参
- 如果调用的函数 在定义时有形参,那么在调用的时候就应该传递参数
调用时,实参的个数和先后顺序应该和定义函数中要求的一致
如果调用的函数有返回值,那么就可以用一个变量来进行保存这个值
3. 作用域
在一个函数中定义的变量,只能在本函数中用(局部变量)
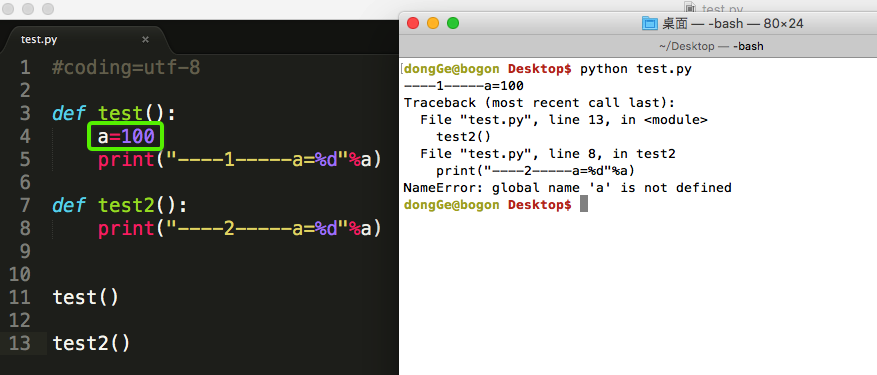
在函数外定义的变量,可以在所有的函数中使用(全局变量)
6.0 强化练习
6.1 函数应用:学生管理系统
1 | import time |
6.2 递归函数(了解)
<1>什么是递归函数
通过前面的学习知道一个函数可以调用其他函数。
如果一个函数在内部不调用其它的函数,而是自己本身的话,这个函数就是递归函数。
<2>递归函数的作用
举个例子,我们来计算阶乘 n! = 1 * 2 * 3 * ... * n
解决办法1:
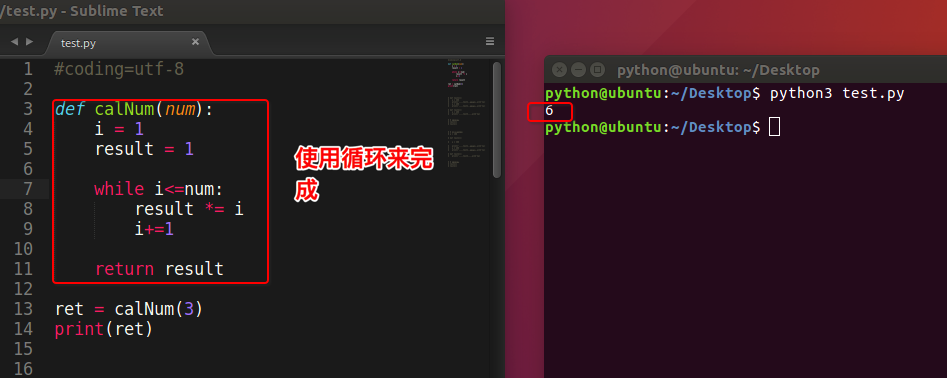
看阶乘的规律
1 | 1! = 1 |
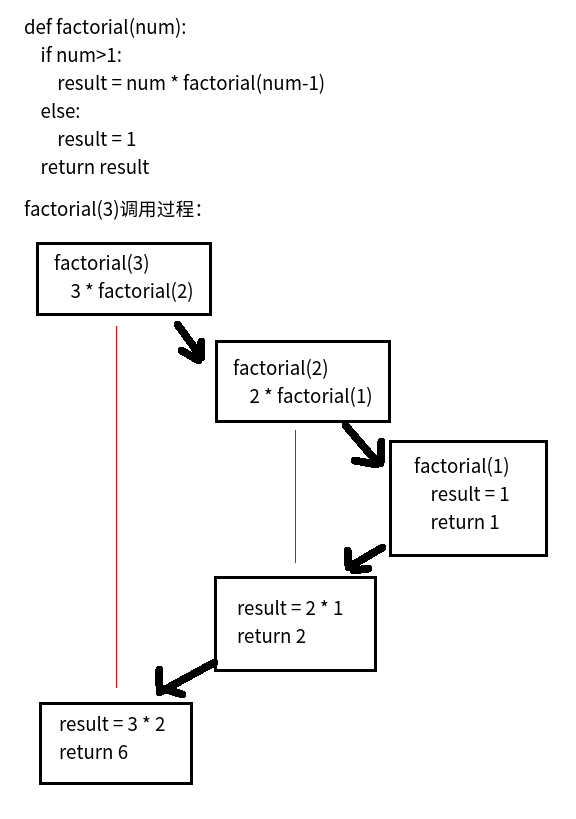
解决办法2:
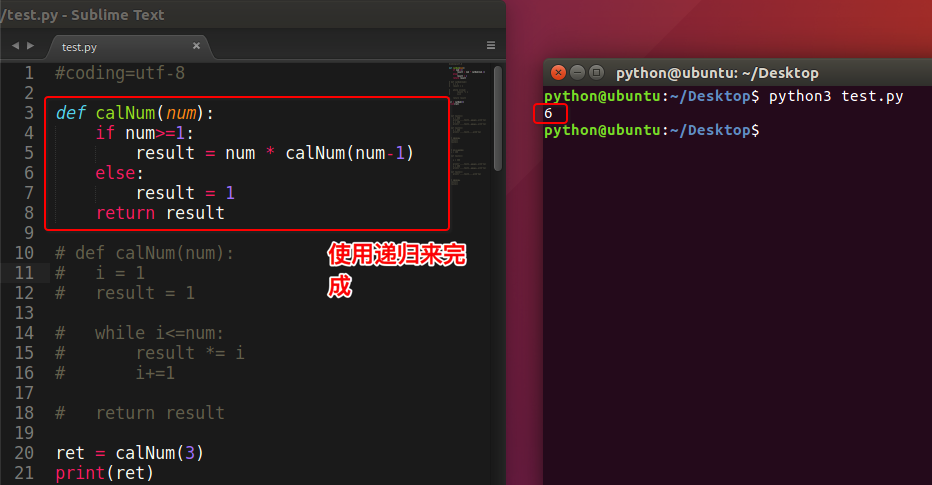
原理
6.3 eval()函数
(类似于序列化和反序列化的桥梁)
字符串转python数据,python数据转字符串
可以传入指定字符串作为参数,如果字符串里是一个有效的表达式,就会被执行
1 | a = 10 |
上面代码中,字符串‘a+20’ 通过eval函数 变成运算 a+20
1 | str02 = '3*2' |
上面代码中,字符串‘3*2’ 通过eval函数 变成运算 3×2
1 | str03 = "abc/5" |
上面代码会报错,看下下面的
1 | abc = 10 |
由于提前定义了abc=10,所以abc/5就是可以正常运行的表达式
把字符串转成对应的类型
- 转成整形
1 | str01 = '123' |
- 还可以用eval来实现
1 | num2 = eval(str01) |
- 转为浮点
1 | str02 = '10.5' |
- 下面 的转换会报错
1 | str04 = 'a123' |
6.4 匿名函数
(相当于js中的箭头函数)
用lambda关键词能创建小型匿名函数。这种函数得名于省略了用def声明函数的标准步骤。
lambda函数的语法只包含一个语句,如下:
1 | lambda [arg1 [,arg2,.....argn]]:expression |
如下实例:
1 | sum = lambda arg1, arg2: arg1 + arg2 |
以上实例输出结果:
1 | Value of total : 30 |
Lambda函数能接收任何数量的参数但只能返回一个表达式的值
匿名函数不能直接调用print,因为lambda需要一个表达式
应用场合
函数作为参数传递
自己定义函数
1
2
3
4
5
6
7
8
9def fun(a, b, opt):
print("a = " % a)
print("b = " % b)
print("result =" % opt(a, b))
...
fun(1, 2, lambda x,y:x+y)
a = 1
b = 2
result = 3作为内置函数的参数
想一想,下面的数据如何指定按age或name排序?
1 | stus = [ |
按name排序:
1 | stus.sort(key = lambda x: x['name']) |
按age排序:
1 | stus.sort(key = lambda x: x['age']) |
6.5 给程序传参数
1 | import sys |
运行结果:

6.6 range()函数
python中 range() 函数可创建一个整数列表,一般用在 for 循环中
注意:range函数在python2和python3中有些区别
在python2返回的是一个列表
在python3中返回的是一个迭代器 ,大家可以当做一个列表来使用,关于迭代器后面高级知识中讲解
基本语法
1 | range(start, stop[, step]) |
来使用一下
1 | range(0,10) |
负数也可以,注意:如果 如果开始比结束的数字小,那么步长也要是负值
1 | range(5,-10,-1) |
继续看下练习:
1 | list01 = [0, 1, 2, 3, 4, 5] |
6.7 列表推导式
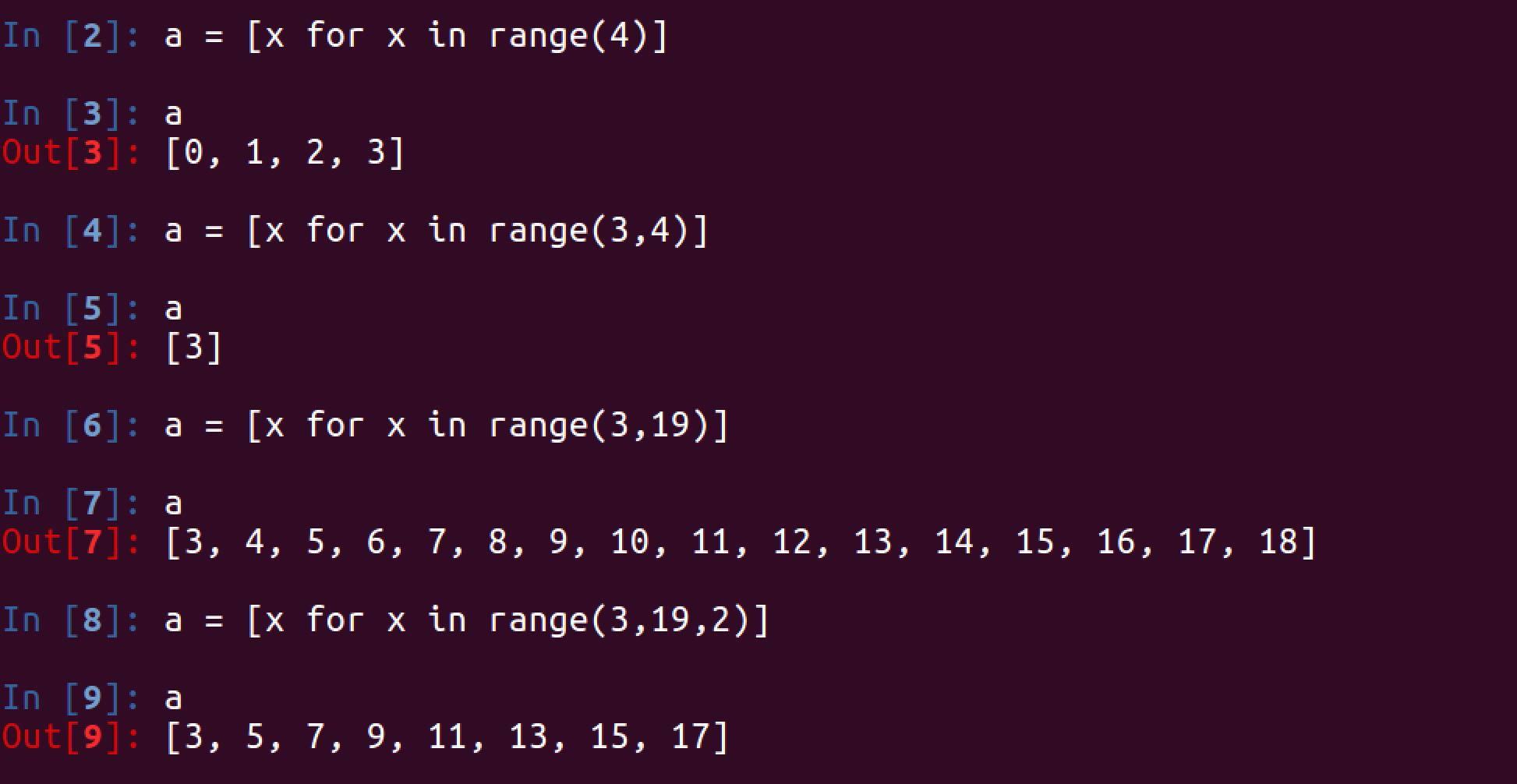
所谓的列表推导式,就是指的轻量级循环创建列表
1. 基本的方式
2. 在循环的过程中使用if
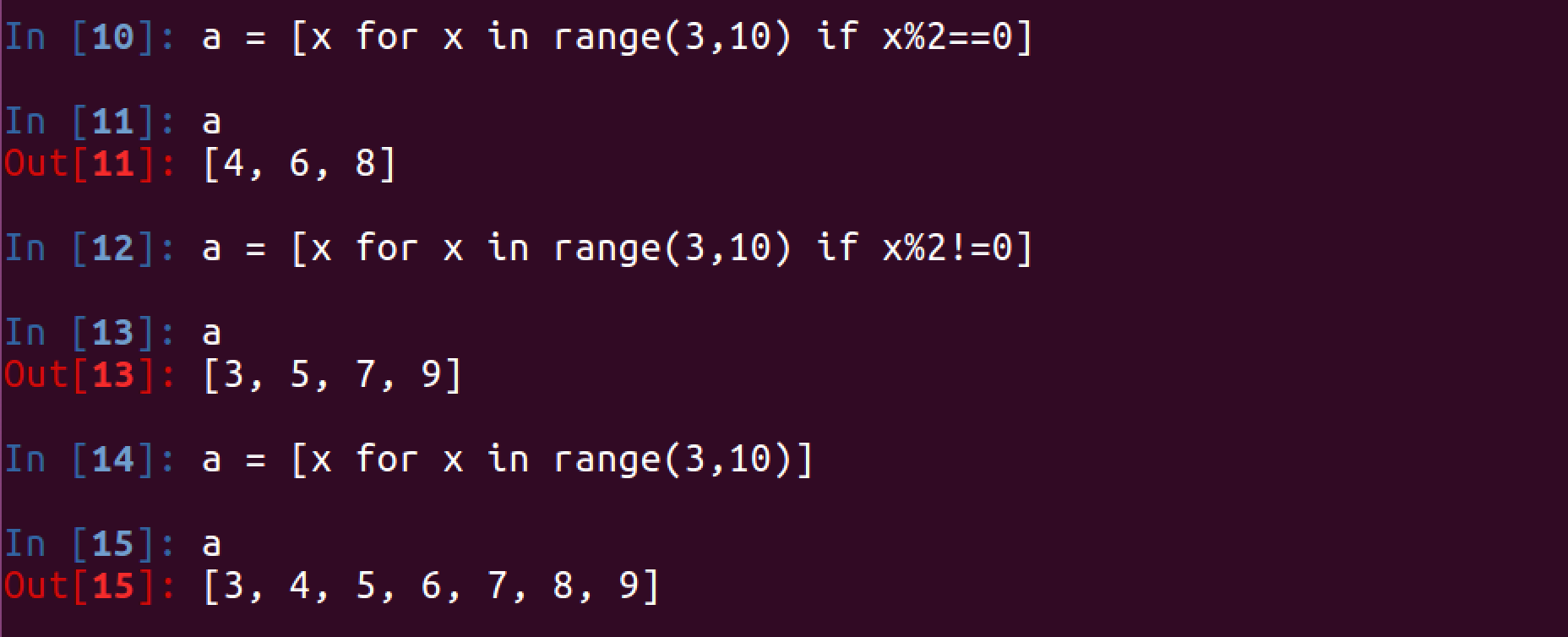
3. 2个for循环

4. 3个for循环
练习
请写出一段 Python 代码实现分组一个 list 里面的元素,比如 [1,2,3,…100]变成 [[1,2,3],[4,5,6]….]
参考答案:
1 | a = [x for x in range(1,101)] |
6.8 set、list、tuple(集合列表元组)
set是集合类型
1 | s01 = {1, 2, 3, 4, 5} |
可以循环
1 | #可以循环使用 |
集合的一些注意事项
怎么创建空集合
1
2
3
4
5
6
7
8
9s01 = {}
print(type(s01)) # 字典
s02 = {1, 2, 3}
print(type(s02)) # 集合
# 创建空的集合
s03 = set()
print(type(s03))不允许元素重复
set、list、tuple之间可以相互转换
1 | # 定义一个列表 |
使用set,可以快速的完成对list中的元素去重复的功能
1 | list01 = [11, 4, 22, 3, 33, 55, 6, 77, 22, 55, 11, 3] |
7.0 文件操作、综合应用
7.1 文件操作介绍
<1>什么是文件
示例如下:
<2>文件的作用
大家应该听说过一句话:“好记性不如烂笔头”。
不仅人的大脑会遗忘事情,计算机也会如此,比如一个程序在运行过程中用了九牛二虎之力终于计算出了结果,试想一下如果不把这些数据存放起来,相比重启电脑之后,“哭都没地方哭了”
可见,在把数据存储起来有做么大的价值
使用文件的目的:
就是把一些存储存放起来,可以让程序下一次执行的时候直接使用,而不必重新制作一份,省时省力
7.2 文件的打开与关闭
想一想:
如果想用word编写一份简历,应该有哪些流程呢?
- 打开word软件,新建一个word文件
- 写入个人简历信息
- 保存文件
- 关闭word软件
同样,在操作文件的整体过程与使用word编写一份简历的过程是很相似的
- 打开文件,或者新建立一个文件
- 读/写数据
- 关闭文件
<1>打开文件
在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
open(文件名,访问模式)
示例如下:
1 | f = open('test.txt', 'w') |
说明:
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
<2>关闭文件
close( )
示例如下:
1 | # 新建一个文件,文件名为:test.txt |
7.3 文件的读写
<1>写数据(write)
使用write()可以完成向文件写入数据
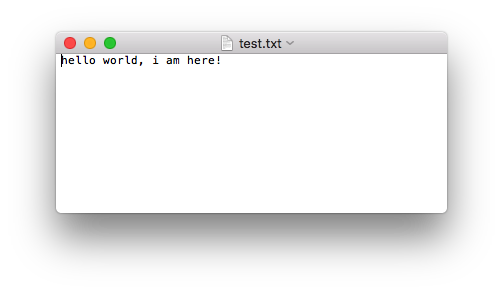
demo: 新建一个文件 file_write_test.py,向其中写入如下代码:
1 | f = open('test.txt', 'w') |
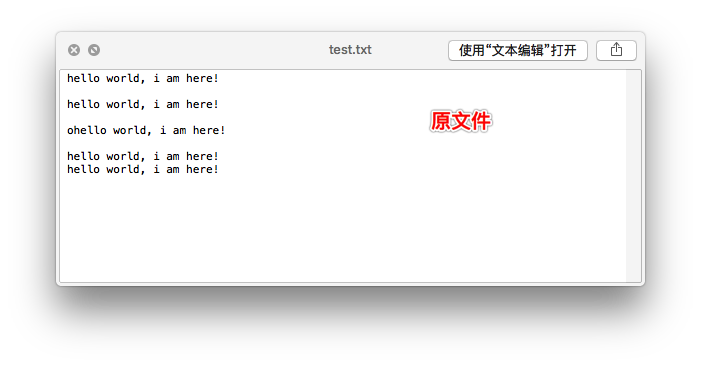
运行之后会在file_write_test.py文件所在的路径中创建一个文件test.txt,其中数据如下:
注意:
- 如果文件不存在那么创建,如果存在那么就先清空,然后写入数据
<2>读数据(read)
使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
demo: 新建一个文件file_read_test.py,向其中写入如下代码:
1 | f = open('test.txt', 'r') |
运行现象:
1 | hello |
注意:
- 如果用open打开文件时,如果使用的”r”,那么可以省略,即只写
open('test.txt')
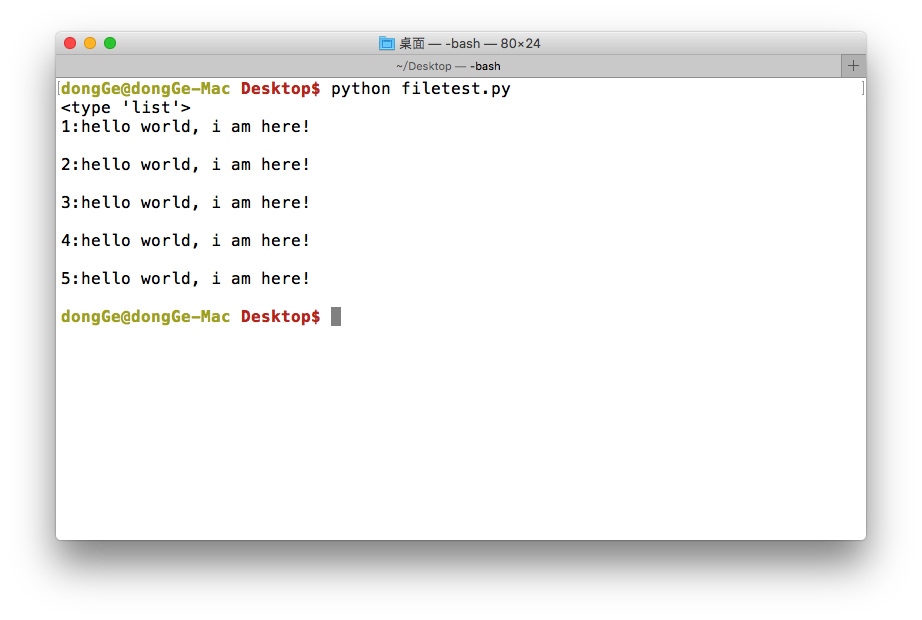
<3>读数据(readlines)
就像read没有参数时一样,readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
1 | #coding=utf-8 |
运行现象:
<4>读数据(readline)
1 | #coding=utf-8 |
想一想:
如果一个文件很大,比如5G,试想应该怎样把文件的数据读取到内存然后进行处理呢?
7.4 应用1:制作文件的备份
任务描述
- 输入文件的名字,然后程序自动完成对文件进行备份
参考代码
1 | # 提示输入文件 |
注意⚠️:文件打开了一定要记得关闭
7.5 文件、文件夹的相关操作
有些时候,需要对文件进行重命名、删除等一些操作,python的os模块中都有这么功能
1. 文件重命名
os模块中的rename()可以完成对文件的重命名操作
rename(需要修改的文件名, 新的文件名)
1 | import os |
2. 删除文件
os模块中的remove()可以完成对文件的删除操作
remove(待删除的文件名)
1 | import os |
3. 创建文件夹
1 | import os |
4. 删除文件夹
1 | import os |
5. 获取目录列表
1 | import os |
6. 获取当前目录
1 | import os |
7. 改变默认目录
1 | import os |
7.6 应用:批量修改文件名
<1>运行过程演示
运行程序之前

运行程序之后

<2>参考代码
1 | # 批量在文件名前加前缀 |
作业:
把前缀名字去掉
7.7 综合应用:学生管理系统(文件版)
1 | import time |
注意:
- 以上程序,在运行之前请先建立info_data.data文件,并且写入一对中括号[]即可
- 等到后面讲解完
异常之后就解决了这个问题
8.0 面向对象基础(一)
8.1 面向对象编程介绍
想一想:
请用程序描述如下事情:
- A同学报道登记信息
- B同学报道登记信息
- C同学报道登记信息
- A同学做自我介绍
- B同学做自我介绍
- C同学做自我介绍
1 | stu_a = { |
考虑现实生活中,我们的思维方式是放在学生这个个人上,是学生做了自我介绍。而不是像我们刚刚写出的代码,先有了介绍的行为,再去看介绍了谁。
用我们的现实思维方式该怎么用程序表达呢?
1 | stu_a = Student(个人信息) |
- 面向过程:根据业务逻辑从上到下写代码
- 面向对象:将数据与函数绑定到一起,进行封装,这样能够更快速的开发程序,减少了重复代码的重写过程
面向过程编程最易被初学者接受,其往往用一长段代码来实现指定功能,开发过程的思路是将数据与函数按照执行的逻辑顺序组织在一起,数据与函数分开考虑。
今天我们来学习一种新的编程方式:面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)
1)解决菜鸟买电脑的故事
第一种方式:
1)在网上查找资料
2)根据自己预算和需求定电脑的型号 外星人 顶配 3W7
3)去中关村电脑城找到各种店无法甄别真假 随便找了一家
4)找到业务员,业务员推荐了另外一款 配置更高价格便宜,才 1W
5)砍价30分钟 付款9999
6)成交
回去之后发现各种问题
第二种方式 :
1)找一个靠谱的电脑高手
2)给钱交易
面向对象和面向过程都是解决问题的一种思路而已
- 买电脑的第一种方式:
- 强调的是步骤、过程、每一步都是自己亲自去实现的
- 这种解决问题的思路我们就叫做面向过程
- 买电脑的第二种方式:
- 强调的是电脑高手, 电脑高手是处理这件事的主角,对我们而言,我们并不必亲自实现整个步骤只需要调用电脑高手就可以解决问题
- 这种解决问题的思路就 是面向对象
- 用面向对象的思维解决问题的重点
- 当遇到一个需求的时候不用自己去实现,如果自己一步步实现那就是面向过程
- 应该找一个专门做这个事的人来做
- 面向对象是基于面向过程的
- 买电脑的第一种方式:
2)解决吃烤鸭的问题
第一种方式(面向过程):
1)养鸭子
2)鸭子长成
3)杀
4)作料
5)烹饪
6)吃
7)卒
第二种方式(面向对象):
1)找个卖烤鸭的人
2)给钱 交易
3)吃
4)胖6斤
>

这里注意面向对象中出现的层级,吃烤鸭的人只会和啤酒鸭师傅打交道,但是接触不到饲养员。
需要了解的定义性文字:
面向对象(object-oriented ;简称: OO) 至今还没有统一的概念 我这里把它定义为: 按人们 认识客观世界的系统思维方式,采用基于对象(实体) 的概念建立模型,模拟客观世界分析、设 计、实现软件的办法。
面向对象编程(Object Oriented Programming-OOP) 是一种解决软件复用的设计和编程方法。 这种方法把软件系统中相近相似的操作逻辑和操作 应用数据、状态,以类的型式描述出来,以对象实例的形式在软件系统中复用,以达到提高软件开发效率的作用。
8.2 类和对象(重点)
面向对象编程的2个非常重要的概念:类和对象
对象是面向对象编程的核心,在使用对象的过程中,为了将具有共同特征和行为的一组对象抽象定义,提出了另外一个新的概念——类
类就相当于制造飞机时的图纸,用它来进行创建的飞机就相当于对象
1. 类
1 | 人以类聚 物以群分。 |
2. 对象
1 | 某一个具体存在的事物 ,在现实世界中可以是看得见摸得着的。 |
3. 类和对象之间的关系
小总结:类就是创建对象的模板
4. 练习:区分类和对象
1 | 汽车:类 |
5. 类的构成
类(Class) 由3个部分构成
- 类的名称:类名
- 类的属性:一组数据
- 类的方法:允许对进行操作的方法 (行为)
<1> 举例:
1)人类设计,只关心3样东西:
- 事物名称(类名):人(Person)
- 属性:身高(height)、年龄(age)
- 方法(行为/功能):跑(run)、打架(fight)
2)狗类的设计
- 类名:狗(Dog)
- 属性:品种 、毛色、性别、名字、 腿儿的数量
- 方法(行为/功能):叫 、跑、咬人、吃、摇尾巴

6. 类的抽象
如何把日常生活中的事物抽象成程序中的类?
拥有相同(或者类似)属性和行为的对象都可以抽像出一个类
方法:一般名词都是类(名词提炼法)
<1> 坦克发射3颗炮弹轰掉了2架飞机
- 坦克–》可以抽象成 类
- 炮弹–》可以抽象成类
- 飞机-》可以抽象成类
<2> 【想一想】如下图中,有哪些类呢?

说明:
向日葵
类名: xrk
属性: 颜色
行为: 放阳光
豌豆
类名: wd
属性: 颜色 、发型,血量
行为:发炮, 摇头
坚果:
类名:jg
属性:血量 类型
行为:阻挡;
僵尸
- 类名:js
- 属性:颜色、血量、 类型、速度
- 行为:走 跑跳 吃 死
8.3 定义类
定义一个类,格式如下:
1 | class 类名: |
demo:定义一个Cat类
1 | class Cat: |
注意方法的缩进
8.4 创建对象
python中,可以根据已经定义的类去创建出一个或多个对象。
创建对象的格式为:
1 | 对象名1 = 类名() |
创建对象demo:
1 | class Hero(object): # 新式类定义形式 |
说明:
- 当创建一个对象时,就是用一个模子,来制造一个实物

问题:
对象既然有实例方法,是否也可以有自己的属性?
8.5 添加和获取对象的属性
1 | class Cat: |
问题:
对象创建并添加属性后,能否在类的实例方法里获取这些属性呢?如果可以的话,应该通过什么方式?
8.6 在方法内通过self获取对象属性
1 | class Cat: |
问题:
创建对象后再去添加属性有点不合适,有没有简单的办法,可以在创建对象的时候,就已经拥有这些属性?
8.7 魔法方法__init__()方法
1 | class Cat: |
说明:
__init__()方法,在创建一个对象时默认被调用,不需要手动调用__init__(self)中的self参数,不需要开发者传递,python解释器会自动把当前的对象引用传递过去。
问题:
在类的方法里定义属性的固定值,则每个对象实例变量的属性值都是相同的。
一个游戏里往往有很多不同的英雄,能否让实例化的每个对象,都有不同的属性值呢?
8.8 有参数的__init__()方法
1 | class Cat: |
说明:
- 通过一个类,可以创建多个对象,就好比 通过一个模具创建多个实体一样
__init__(self)中,默认有1个参数名字为self,如果在创建对象时传递了2个实参,那么__init__(self)中出了self作为第一个形参外还需要2个形参,例如def __init__(self, new_name, new_age)
注意:
- 在类内部获取 属性 和 实例方法,通过self获取;
- 在类外部获取 属性 和 实例方法,通过对象名获取。
- 如果一个类有多个对象,每个对象的属性是各自保存的,都有各自独立的地址;
- 但是实例方法是所有对象共享的,只占用一份内存空间。类会通过self来判断是哪个对象调用了实例方法。
8.9 魔法方法__str__()方法
1 | class Cat: |
说明:
- 在python中方法名如果是
__xxxx__()的,那么就有特殊的功能,因此叫做“魔法”方法 - 当使用print输出对象的时候,默认打印对象的内存地址。如果类定义了
__str__(self)方法,那么就会打印从在这个方法中return的数据 __str__方法通常返回一个字符串,作为这个对象的描述信息
8.10 魔法方法__del__()方法
创建对象后,python解释器默认调用__init__()方法;
当删除对象时,python解释器也会默认调用一个方法,这个方法为__del__()方法
1 | class Hero(object): |
总结
- 当有变量保存了一个对象的引用时,此对象的引用计数就会加1;
- 当使用del() 删除变量指向的对象时,则会减少对象的引用计数。如果对象的引用计数不为1,那么会让这个对象的引用计数减1,当对象的引用计数为0的时候,则对象才会被真正删除(内存被回收)。
8.11 参考案例:烤地瓜
为了更好的理解面向对象编程,下面以“烤地瓜”为案例,进行分析
1. 分析“烤地瓜”的属性和方法
示例属性如下:
- cookedLevel : 这是数字;0~3表示还是生的,超过3表示半生不熟,超过5表示已经烤好了,超过8表示已经烤成木炭了!我们的地瓜开始时时生的
- cookedString : 这是字符串;描述地瓜的生熟程度
- condiments : 这是地瓜的配料列表,比如番茄酱、芥末酱等
示例方法如下:
cook(): 把地瓜烤一段时间addCondiments(): 给地瓜添加配料__init__(): 设置默认的属性__str__(): 让print的结果看起来更好一些
2. 定义类,并且定义__init__()方法
1 | #定义`地瓜`类 |
3. 添加”烤地瓜”方法
1 | #烤地瓜方法 |
4. 基本的功能已经有了一部分,赶紧测试一下
把上面2块代码合并为一个程序后,在代码的下面添加以下代码进行测试
1 | mySweetPotato = SweetPotato() |
完整的代码为:
1 | class SweetPotato: |

5. 测试cook方法是否好用
在上面的代码最后面添加如下代码:
1 | print("------接下来要进行烤地瓜了-----") |
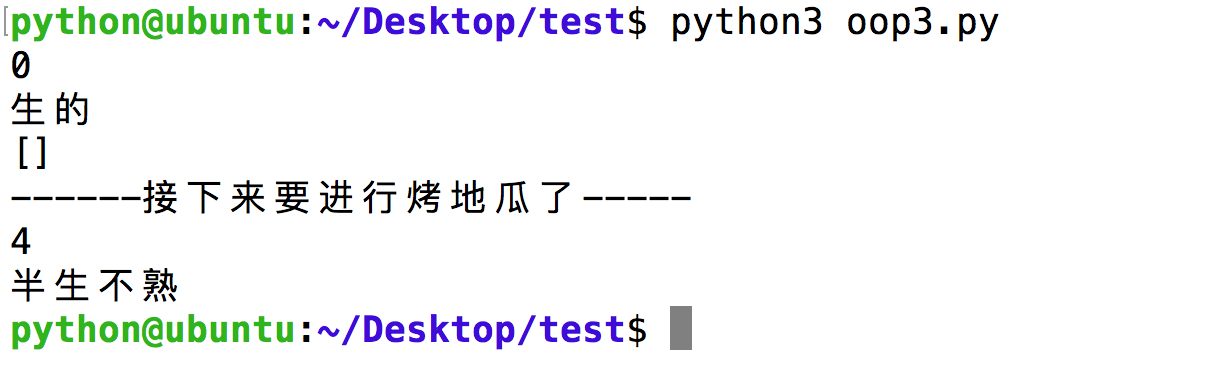
6. 定义addCondiments()方法和__str__()方法
1 | def __str__(self): |
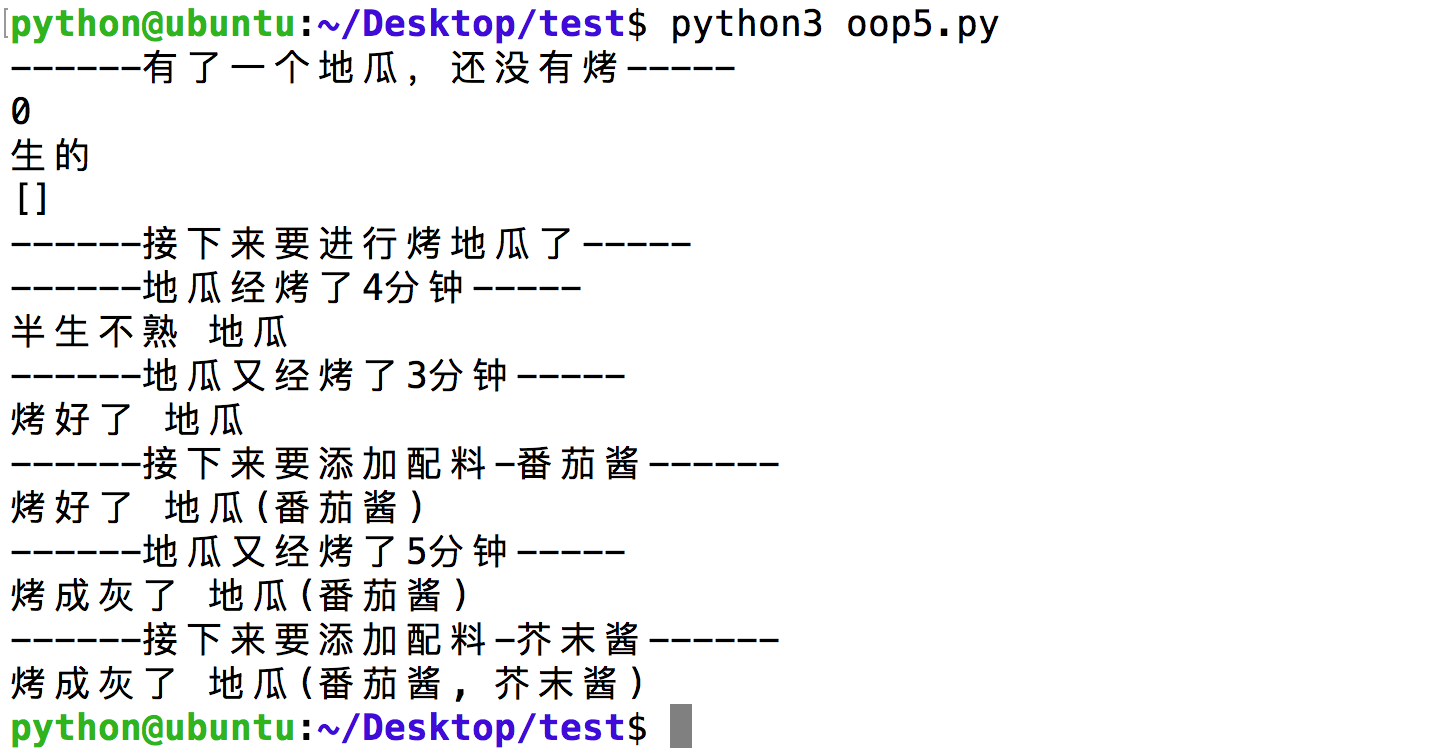
7. 再次测试
完整的代码如下:
1 | class SweetPotato: |
9.0 面向对象基础(二)
9.1 参考案例应用:存放家具
1 | # 定义一个home类 |
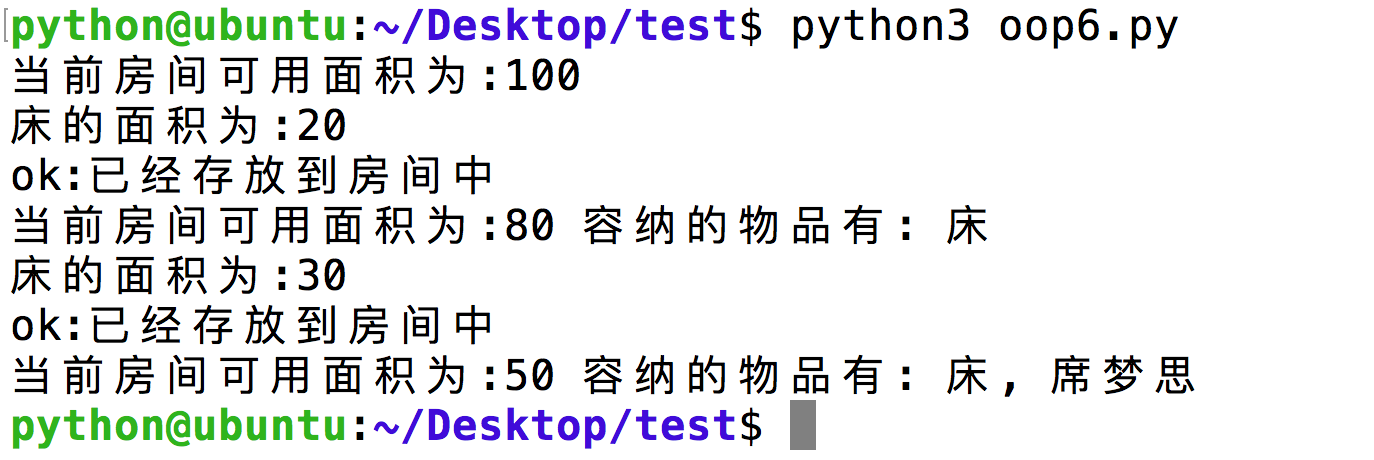
总结:
- 如果一个对象与另外一个对象有一定的关系,那么一个对象可用是另外一个对象的属性
思维升华:
- 添加“开、关”灯,让房间、床一起亮、灭
9.2 私有属性和私有方法
私有权限:在属性名和方法名 前面 加上两个下划线 __
1.私有属性
1 | class Person: |
2.私有方法
1 | class Person: |
总结
- 类的私有属性 和 私有方法,都不能通过对象直接访问,但是可以在本类内部访问;
- 私有属性 和 私有方法 往往用来处理类的内部事情,不通过对象处理,起到安全作用。
9.3 继承介绍以及单继承
1. 现实中的继承
在现实生活中,继承一般指的是子女继承父辈的财产,如下图

搞不好,结果如下..

2. 程序中的继承
- 在程序中,继承描述的是多个类之间的所属关系。
- 一个类A里面的属性和方法可以通过继承的方式,传递到类B里。
- 那么类A就是基类,也叫做父类;类B就是派生类,也叫做子类。
1 | # 父类 |
9.4 继承(单继承):子类只继承一个父类

- 武林高手,有一身高深武功,需要有人来继承衣钵。
- 少年,我看你骨骼精奇,是万中无一的武学奇才,维护世界和平就靠你了,我这有本秘籍-《Python核心编程》
- 高手收了很多个徒弟,徒弟继承了师傅的高深武功
1 | # 定义一个Master类 master精通, 大师的意思 |
说明:
- 江湖中门派众多,徒弟不可背叛师门,只能学习自家功夫,只能有一个师傅,这就是单继承
- 虽然子类没有定义
__init__方法初始化属性,也没有定义实例方法,但是父类有。所以只要创建子类的对象,就默认执行了那个继承过来的__init__方法
总结:
- 子类在继承的时候,在定义类时,小括号()中为父类的名字
- 父类的属性、方法,会被继承给子类
- 只有一个父类的继承,叫做单继承
后续:
- wukong比较聪明,很快发明了自己的新招式,弹指神通,见后续(子类添加新方法)
9.5 继承(单继承):子类添加新方法

- wukong比较聪明,很快发明了自己的新招式,弹指神通
1 | # 定义一个Master类 master精通, 大师的意思 |
总结:
- 子类可以调用自己创建的方法,也可以调用父类的方法
后续:
- wukong很快名声大作,也收了一个徒弟欧布,把自己的武功传授给了徒弟,见后续(多层继承)
9.6 继承:多层继承

- wukong很快名声大作,也收了一个徒弟欧布,把自己的武功传授给了徒弟
- 欧布学会了师父和师爷的武功
1 | # 定义一个Master类 master精通, 大师的意思 |
总结:
- 可以多层继承,子类还可以有子类
后续:
- 欧布天资聪慧,增强了师父和师爷的武功,见后续(重写)
9.7 子类重写父类同名方法
继承:重写
- 欧布天资聪慧,增强了师父和师爷的武功
1 | # 定义一个Master类 master精通, 大师的意思 |
总结:
- 子类写的方法和父类重名,就是对父类方法的重写
- 重写后,子类调用方法,就会执行自己方法里的内容
后续:
- 欧布遇到很多挑战者,很多挑战者必须师父的武功和自己的升级版武功同时使用才能将对方打败,见后续(调用被重写的父类的方法)
9.8 子类里调用父类方法
继承:子类调用父类的方法
- 欧布遇到很多挑战者,很多挑战者必须师父的武功和自己的升级版武功同时使用才能将对方打败,
1 | # 定义一个Master类 master精通, 大师的意思 |
总结:
语法:
1
2
31.父类类名.方法名(self)
2.super(子类类名,self).方法名()
3.super().方法名() 这种用的比较多场景:需要使用父类中方法时,
问:欧布能调用的父类的方法,能否调用父类的父类的方法呢?
1 | # 定义一个Master类 master精通, 大师的意思 |
注意:
1 | Apprentice.yyz(self) |
- 调用父类的方法,父类如果没有会再去父类的父类里找
9.9 属性的继承
继承:子类继承父类属性
- 属性也像方法一样可以被继承使用
1 | # 定义一个Master类 master精通, 大师的意思 |
- 子类也可以对继承的属性进行修改,如下代码
1 | # 定义ApprenticeApprentice类,继承了 Apprentice |
子类不能用super()来调用父类属性 如下代码会报错
```
定义一个Master类 master精通, 大师的意思
class Master:
1
2
3
4
5
6def __init__(self):
self.name = '哈哈派'
print('---Master--init---')
def yyz(self):
print("发出一招-----一阳指")定义Prentice类,继承了 Master
class Apprentice(Master):
1
2
3
4
5
6
7def tzst(self):
print("发出一招-----弹指神通")
def say(self):
# print(Master.name)
# print(super(Apprentice, self).name)
print(super().name)
1 | wukong = Apprentice() |
9.10 私有属性和私有方法是否继承
继承:私有属性和方法能否继承
1 | # 定义一个Master类 master精通, 大师的意思 |
- 结论:私有方法和私有属性无法被继承
可以通过间接方式去使用 如下
1 | # 定义一个Master类 master精通, 大师的意思 |
9.11 多继承
多继承:子类继承多个父类
- wukong生性顽皮,离开师傅独自闯荡,又遇到了自己第二个师傅
1 | # 定义一个Master类 master精通, 大师的意思 |
说明:
- 多继承可以继承多个父类,也继承了所有父类的属性和方法
悟空的两位师傅都有飞檐走壁的轻功,悟空学会的是谁的呢?
1 | # 定义一个Master类 master精通, 大师的意思 |
说明:
- 注意:如果多个父类中有同名的 属性和方法,则默认使用第一个父类的属性和方法(根据类的魔法属性mro的顺序来查找)
- 多个父类中,不重名的属性和方法,不会有任何影响。
10.0 面向对象基础(三)
10.1 修改私有属性的值
如果需要修改一个对象的属性值,通常有2种方法
- 对象名.属性名 = 数据 —-> 直接修改
- 对象名.方法名() —-> 间接修改
私有属性不能直接访问,所以无法通过第一种方式修改,一般的通过第二种方式修改私有属性的值:定义一个可以调用的公有方法,在这个公有方法内访问修改。
1 | class Master(object): |
10.2 多态
所谓多态:定义时的类型和运行时的类型不一样,此时就成为多态 ,多态的概念是应用于Java和C#这一类强类型语言中,而Python崇尚“鸭子类型”。
鸭子类型:虽然我想要一只”鸭子”,但是你给了我一只鸟。 但是只要这只鸟走路像鸭子,叫起来像鸭子,游泳也像鸭子,我就认为这是鸭子。
Python的多态,就是弱化类型,重点在于对象参数是否有指定的属性和方法,如果有就认定合适,而不关心对象的类型是否正确。
- Python伪代码实现Java或C#的多态
1 | class F1(object): |
通俗点理解:定义obj这个变量是说的类型是:F1的类型,但是在真正调用Func函数时给其传递的不一定是F1类的实例对象,有可能是其子类的实例对象, 这种情况就是所谓的多态
- Python “鸭子类型”
1 | class F1(object): |
10.3 封装
将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成“类”,其中数据和函数都是类的成员。
这样隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别;
定义一个学生类 有名字属性 有一个可以计算2个数的和的方法,生成a,b,c,d四个对象
1 | class Student: |
10.4 类属性和实例属性
类对象
- 类可以实例化对象,但是类本身也是对象,称为类对象,在类定义的时候被创建出来并且只有一个
类属性和实例属性
在前面的例子中我们接触到的就是实例属性(对象属性),顾名思义,类属性就是类对象所拥有的属性,它被所有类对象的实例对象所共有,在内存中只存在一个副本,
类属性
1 | class People(object): |
实例属性(对象属性)
1 | class People(object): |
通过实例(对象)去修改类属性
1 | class People(object): |
总结
- 如果需要在类外修改
类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
10.5 静态方法和类方法
1. 类方法
是类对象所拥有的方法,需要用修饰器@classmethod来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以cls作为第一个参数(当然可以用其他名称的变量作为其第一个参数,但是大部分人都习惯以’cls’作为第一个参数的名字,就最好用’cls’了),能够通过实例对象和类对象去访问。
1 | class People(object): |
类方法还有一个用途就是可以对类属性进行修改:
1 | class People(object): |
结果显示在用类方法对类属性修改之后,通过类对象和实例对象访问都发生了改变
2. 静态方法
需要通过修饰器@staticmethod来进行修饰,静态方法不需要多定义参数,可以通过对象和类来访问。
1 | class People(object): |
总结
- 从类方法和实例方法以及静态方法的定义形式就可以看出来,类方法的第一个参数是类对象cls,那么通过cls引用的必定是类对象的属性和方法;
- 实例方法的第一个参数是实例对象self,那么通过self引用的可能是类属性、也有可能是实例属性(这个需要具体分析),不过在存在相同名称的类属性和实例属性的情况下,实例属性优先级更高。
- 静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类实例对象来引用
10.6 __new__方法
__new__和__init__的作用
1 | class A(object): |
总结
__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值- 我们可以将类比作制造商,
__new__方法就是前期的原材料购买环节,__init__方法就是在有原材料的基础上,加工,初始化商品环节
注意点
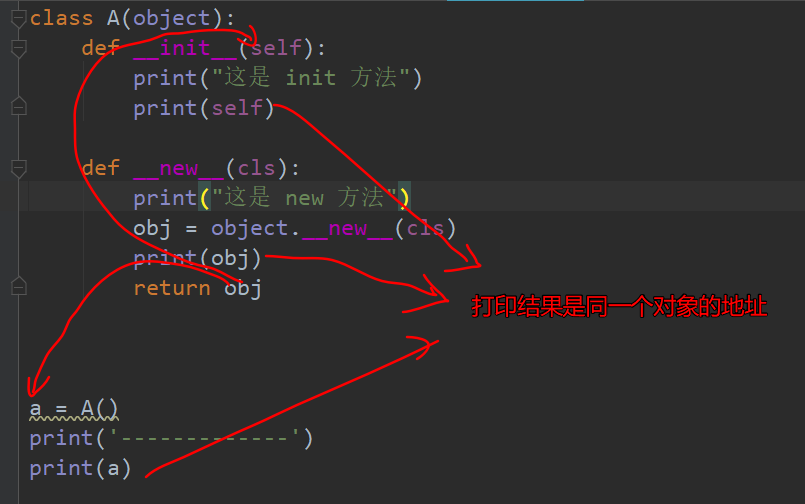
new方法必须返回正确的对象 否则init方法不执行
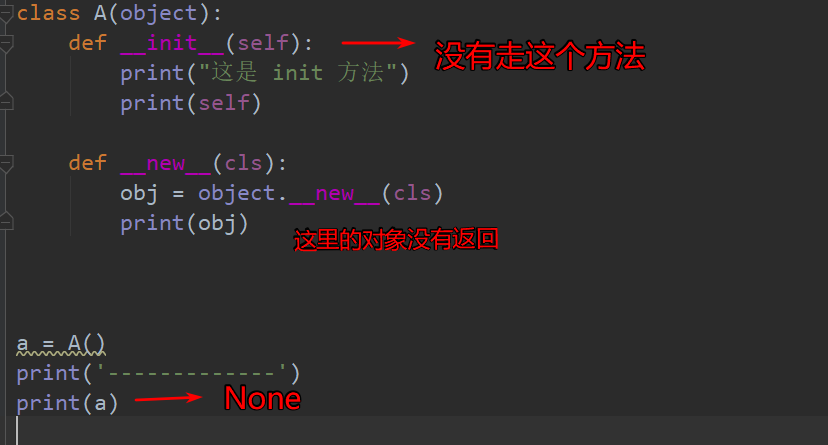
10.7 单例模式
1.定义
单例类
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类
单例模式
是一种设计模式 使用单例类来创建实例对象,只有一个实例,这种设计模式叫做单例模式
2. 创建单例-保证只有1个对象
举个例子,比如皇帝这个类,不会弄出两个对象来
1 | # 实例化一个单例 |
运行结果:
1 | 创建一个新对象 |
3. 创建单例时,如何只执行1次__init__方法
单例类创建对象时,init里的代码重复执行,没有太大意义
1 | # 实例化一个单例 |
运行结果:
1 | 创建一个新对象 |
11.0 异常、模块
11.1 异常介绍
<1>异常简介
看如下示例:
1 | print '-----test--1---' |
运行结果:

说明:
打开一个不存在的文件123.txt,当找不到123.txt 文件时,就会抛出给我们一个IOError类型的错误,No such file or directory:123.txt (没有123.txt这样的文件或目录)
异常:
当Python检测到一个错误时,解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的”异常”
11.2 捕获异常
案例剖析
<1>捕获异常 try…except…
看如下示例:
1 | try: |
运行结果:

说明:
- 此程序看不到任何错误,因为用except 捕获到了IOError异常,并添加了处理的方法
- pass 表示实现了相应的实现,但什么也不做;如果把pass改为print语句,那么就会输出其他信息
小总结:
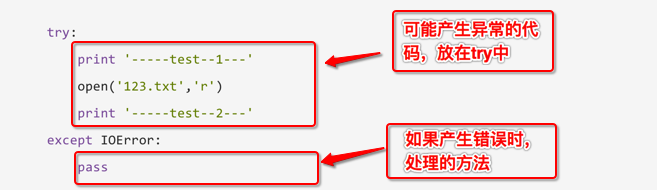
- 把可能出现问题的代码,放在try中
- 把处理异常的代码,放在except中
<2> except捕获多个异常
看如下示例:
1 | try: |
运行结果如下:

想一想:
上例程序,已经使用except来捕获异常了,为什么还会看到错误的信息提示?
答:
except捕获的错误类型是IOError,而此时程序产生的异常为 NameError ,所以except没有生效
修改后的代码为:
1 | try: |
运行结果如下:

实际开发中,捕获多个异常的方式,如下:
1 | #coding=utf-8 |
注意:
- 当捕获多个异常时,可以把要捕获的异常的名字,放到except 后,并使用元组的方式仅进行存储
<3>获取异常的信息描述
1 | print('----1-------') |
执行结果
1 | 执行结果 |
<4>捕获所有异常
1 | print('----1-------') |
如果想查看异常信息
1 | print('----1-------') |
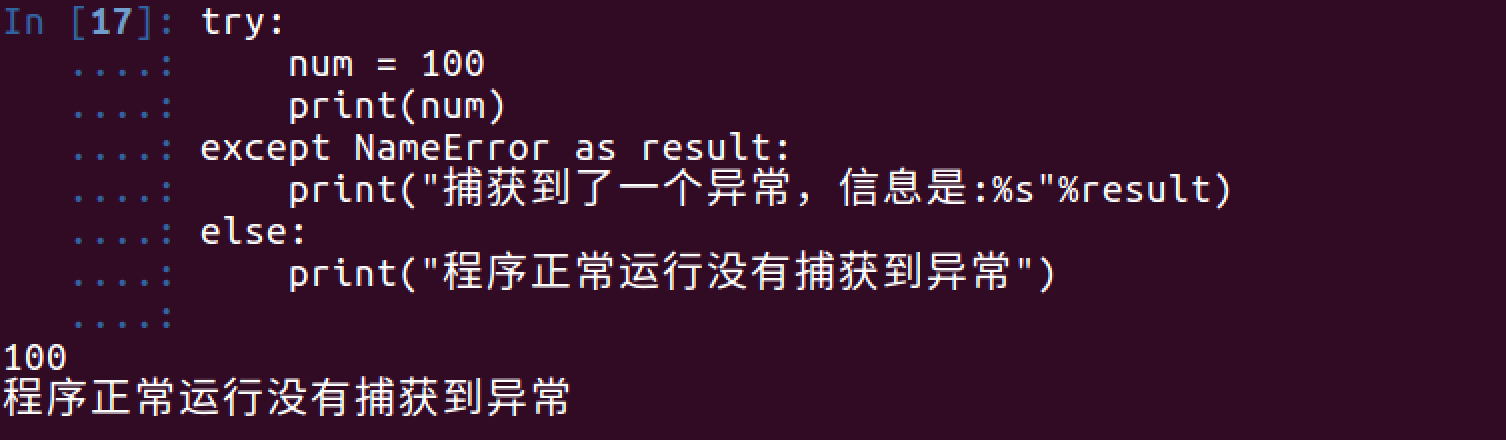
<5> else
咱们应该对else并不陌生,在if中,它的作用是当条件不满足时执行的实行;同样在try…except…中也是如此,即如果没有捕获到异常,那么就执行else中的事情
1 | try: |
运行结果如下:
<6> try…finally…
try…finally…语句用来表达这样的情况:
在程序中,如果一个段代码必须要执行,即无论异常是否产生都要执行,那么此时就需要使用finally。 比如文件关闭,释放锁,把数据库连接返还给连接池等
demo:

说明:
有1/0会报异常 所有f.close不会执行,需要在finally里面执行
11.3 异常的传递
1. try嵌套中
1 | try: |
运行结果:没有这个文件
注意
b = 1/a报异常 但是最近的try没有用except处理,所以继续传递,被外部的try处理掉了
2. 函数嵌套调用中
1 | def test1(): |
运行结果:
1 | Traceback (most recent call last): |
总结:
- 如果try嵌套,那么如果里面的try没有捕获到这个异常,那么外面的try会接收到这个异常,然后进行处理,如果外边的try依然没有捕获到,那么再进行传递。。。
- 如果一个异常是在一个函数中产生的,例如函数A—->函数B—->函数C,而异常是在函数C中产生的,那么如果函数C中没有对这个异常进行处理,那么这个异常会传递到函数B中,如果函数B有异常处理那么就会按照函数B的处理方式进行执行;如果函数B也没有异常处理,那么这个异常会继续传递,以此类推。。。如果所有的函数都没有处理,那么此时就会进行异常的默认处理,即通常见到的那样
- 注意观察上图中,当调用test3函数时,在test1函数内部产生了异常,此异常被传递到test3函数中完成了异常处理,而当异常处理完后,并没有返回到函数test1中进行执行,而是在函数test3中继续执行
11.4 抛出自定义的异常
你可以用raise语句来引发一个异常。异常/错误对象必须有一个名字,且它们应是Error或Exception类的子类
下面是一个引发异常的例子:
1 | class ShortInputException(Exception): |
运行结果如下:
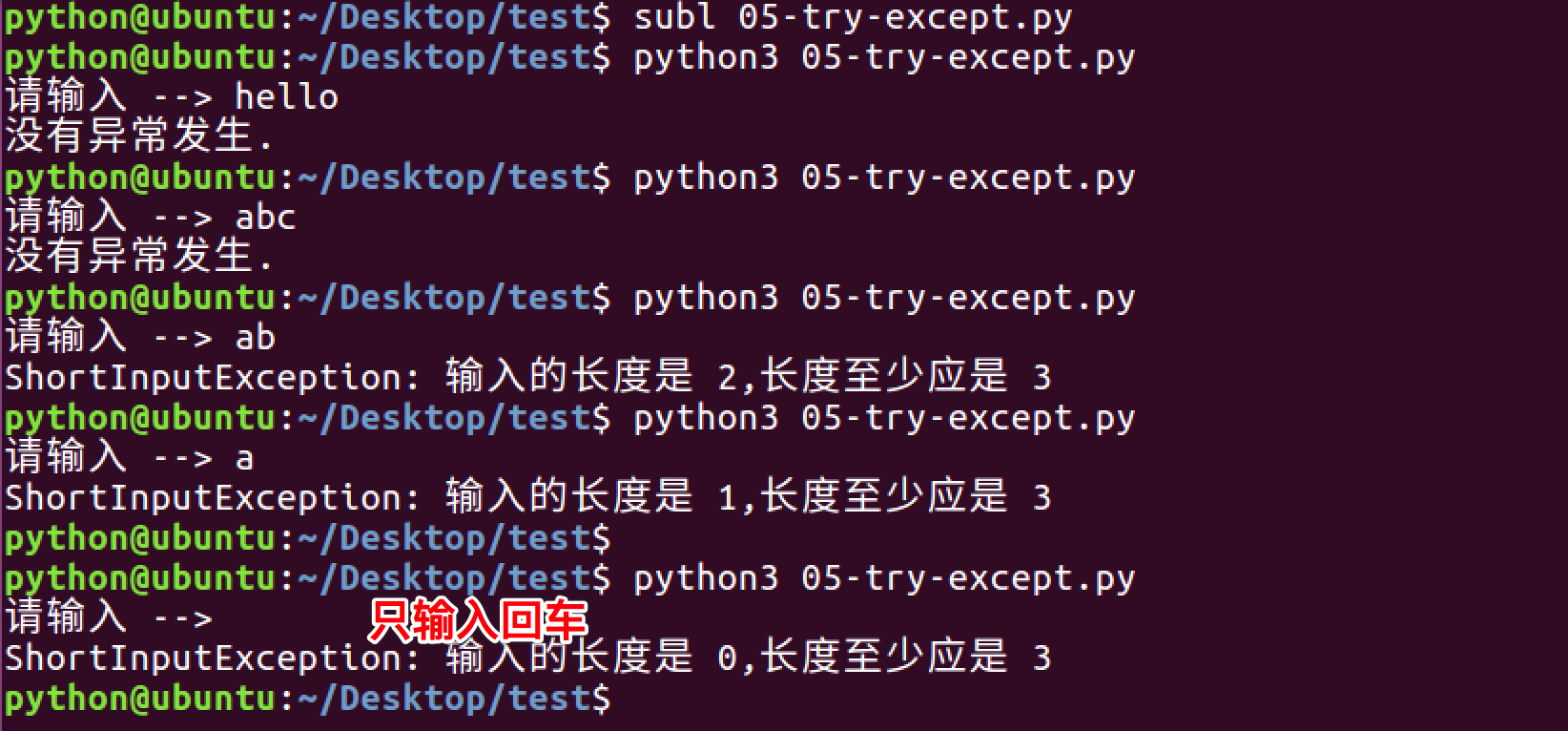
注意
以上程序中,关于代码
1
#super().__init__()
的说明
这一行代码,可以调用也可以不调用,建议调用,因为
__init__方法往往是用来对创建完的对象进行初始化工作,如果在子类中重写了父类的__init__方法,即意味着父类中的很多初始化工作没有做,这样就不保证程序的稳定了,所以在以后的开发中,如果重写了父类的__init__方法,最好是先调用父类的这个方法,然后再添加自己的功能
11.5 异常处理中抛出异常
1 | class Test(object): |
运行结果:
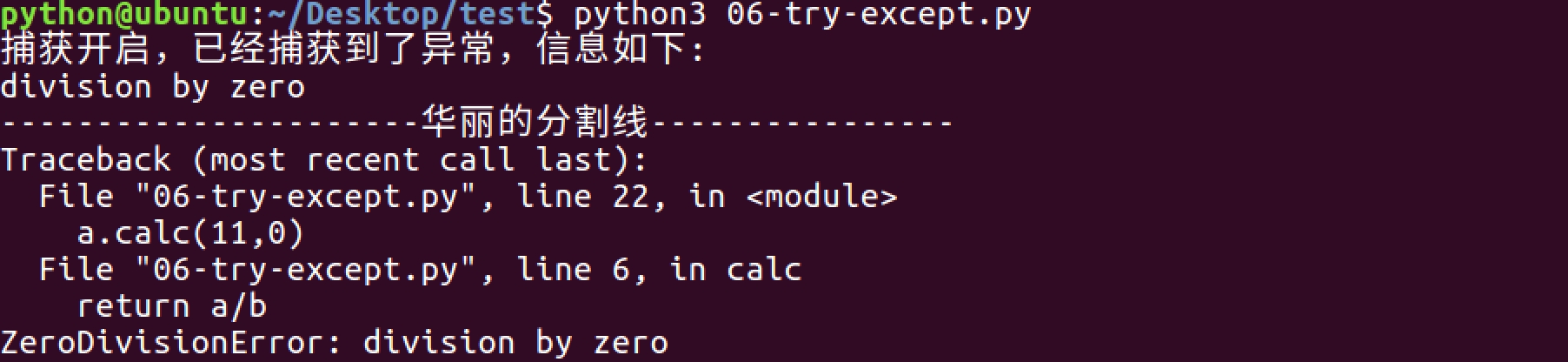
11.6 模块介绍
<1>Python中的模块
有过C语言编程经验的朋友都知道在C语言中如果要引用sqrt函数,必须用语句#include <math.h>引入math.h这个头文件,否则是无法正常进行调用的。
那么在Python中,如果要引用一些其他的函数,该怎么处理呢?
在Python中有一个概念叫做模块(module),这个和C语言中的头文件以及Java中的包很类似,比如在Python中要调用sqrt函数,必须用import关键字引入math这个模块,下面就来了解一下Python中的模块。
说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块
<2>import
在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import math来引入。
形如:
1 | import module1,mudule2... |
当解释器遇到import语句,如果模块在当前的搜索路径就会被导入。
在调用math模块中的函数时,必须这样引用:
1 | 模块名.函数名 |
想一想:
为什么必须加上模块名调用呢?
答:
因为可能存在这样一种情况:在多个模块中含有相同名称的函数,此时如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。所以如果像上述这样引入模块的时候,调用函数必须加上模块名
1 | import math |
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以用下面方法实现:
1 | from 模块名 import 函数名1,函数名2.... |
不仅可以引入函数,还可以引入一些全局变量、类等
注意:
- 通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前一次引入。也就是说假如模块A中有函数function( ),在模块B中也有函数function( ),如果引入A中的function在先、B中的function在后,那么当调用function函数的时候,是去执行模块B中的function函数。
- 如果想一次性引入math中所有的东西,还可以通过from math import *来实现
<3>from…import
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中
语法如下:
1 | from modname import name1[, name2[, ... nameN]] |
例如,要导入模块fib的fibonacci函数,使用如下语句:
1 | from fib import fibonacci |
注意
- 不会把整个fib模块导入到当前的命名空间中,它只会将fib里的fibonacci单个引入
<4>from … import *
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
1 | from modname import * |
注意
- 这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
<5> as
1 | In [1]: import time as tt |
<6>定位模块
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
- 模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
11.7 模块制作
<1>定义自己的模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
比如有这样一个文件test.py,在test.py中定义了函数add
test.py
1 | def add(a,b): |
<2>调用自己定义的模块
那么在其他文件中就可以先import test,然后通过test.add(a,b)来调用了,当然也可以通过from test import add来引入
main.py
1 | import test |
<3>测试模块
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
1 | test.py |
如果此时,在其他py文件中引入了此文件的话,想想看,测试的那段代码是否也会执行呢!
1 | main.py |
运行现象:
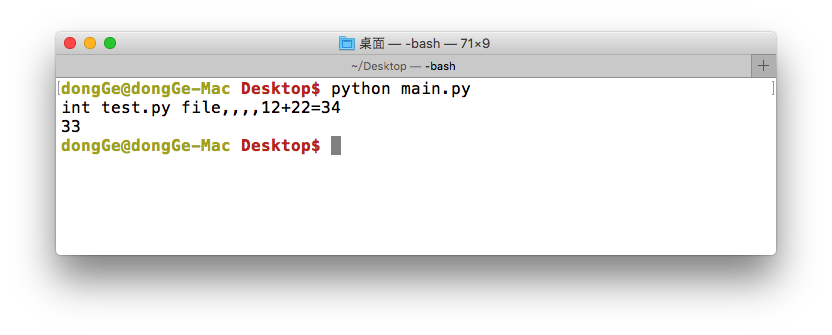
至此,可发现test.py中的测试代码,应该是单独执行test.py文件时才应该执行的,不应该是其他的文件中引用而执行
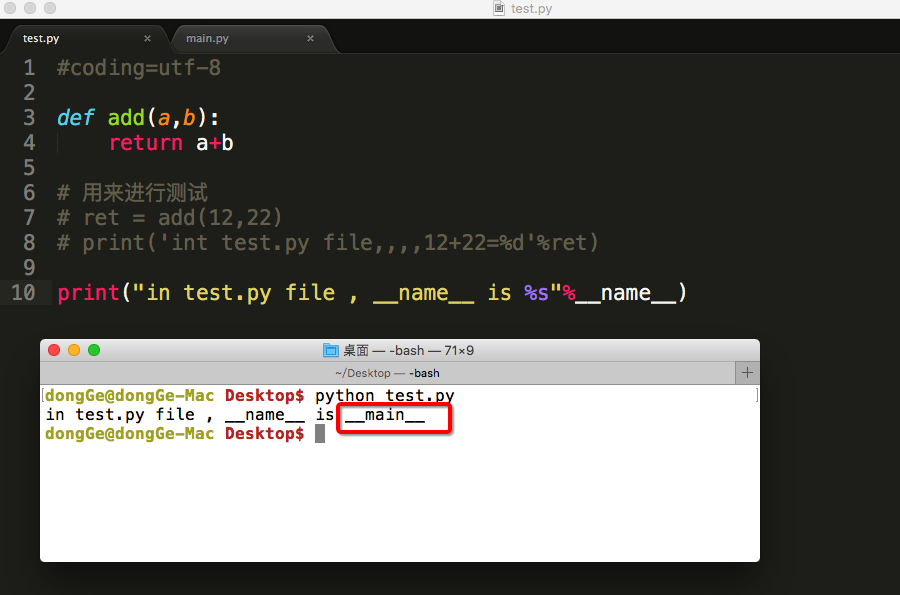
为了解决这个问题,python在执行一个文件时有个变量__name__
直接运行此文件
在其他文件中import此文件
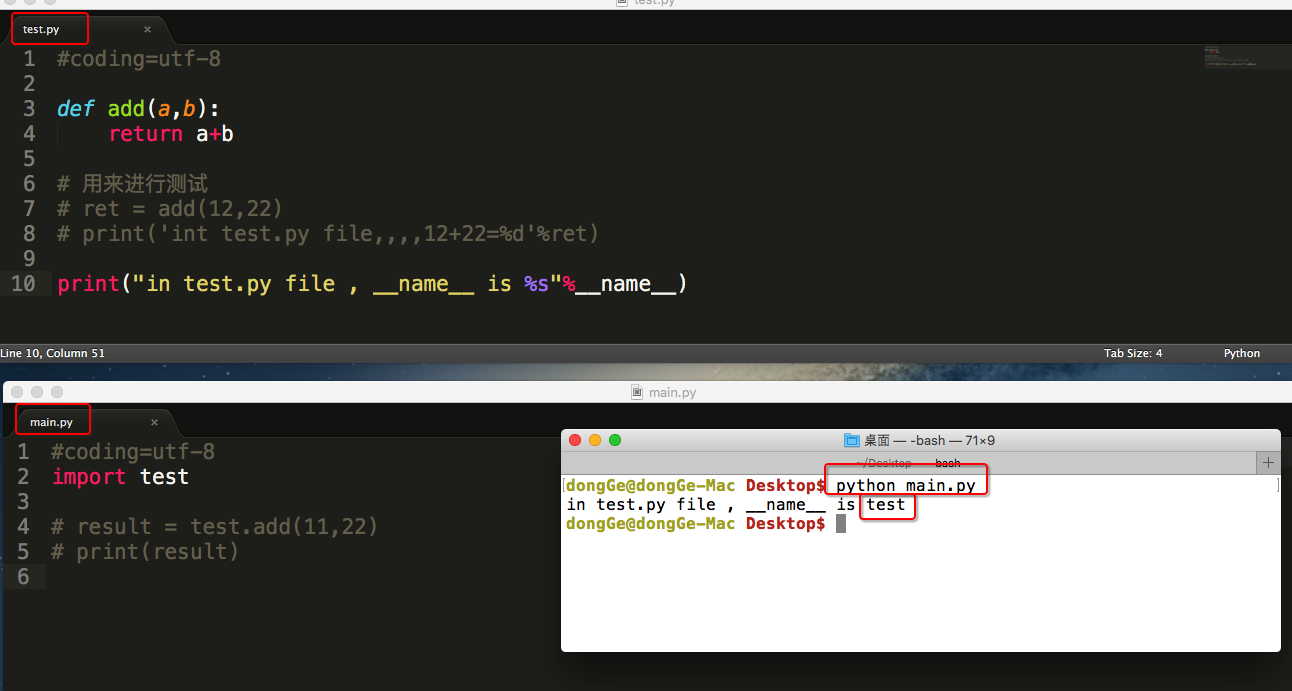
总结:
- 可以根据__name__变量的结果能够判断出,是直接执行的python脚本还是被引入执行的,从而能够有选择性的执行测试代码
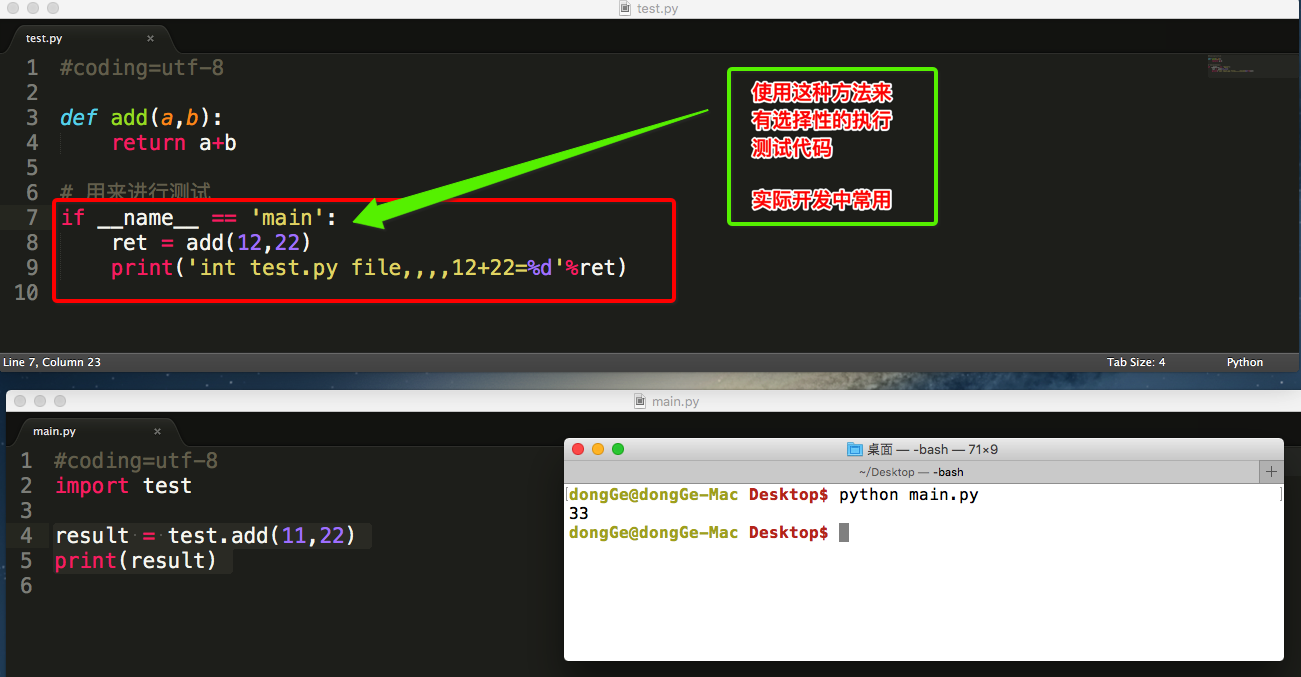
11.8 模块中的__all__
1. 没有__all__
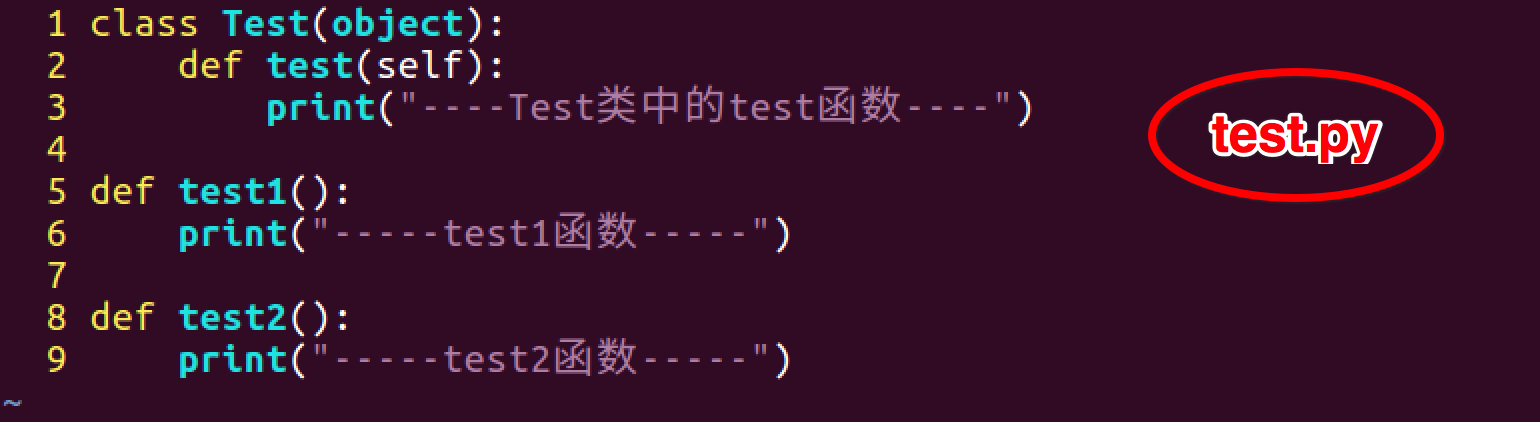

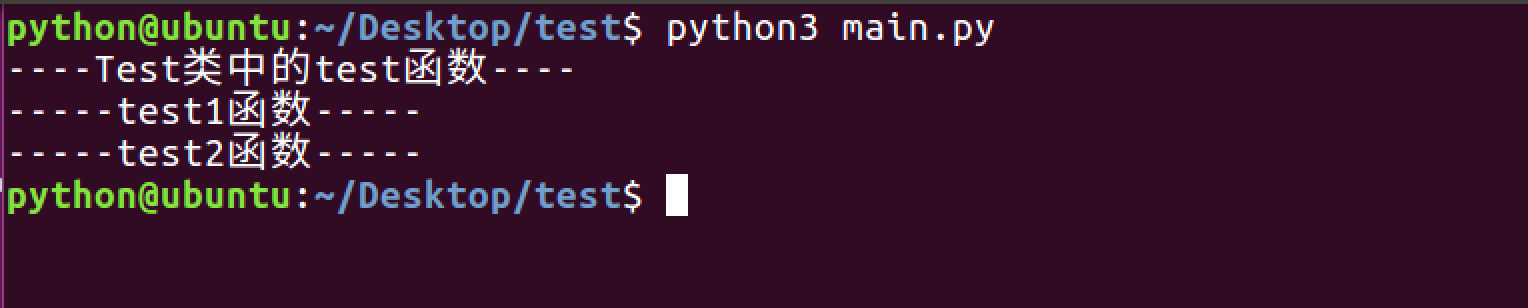
2. 模块中有__all__
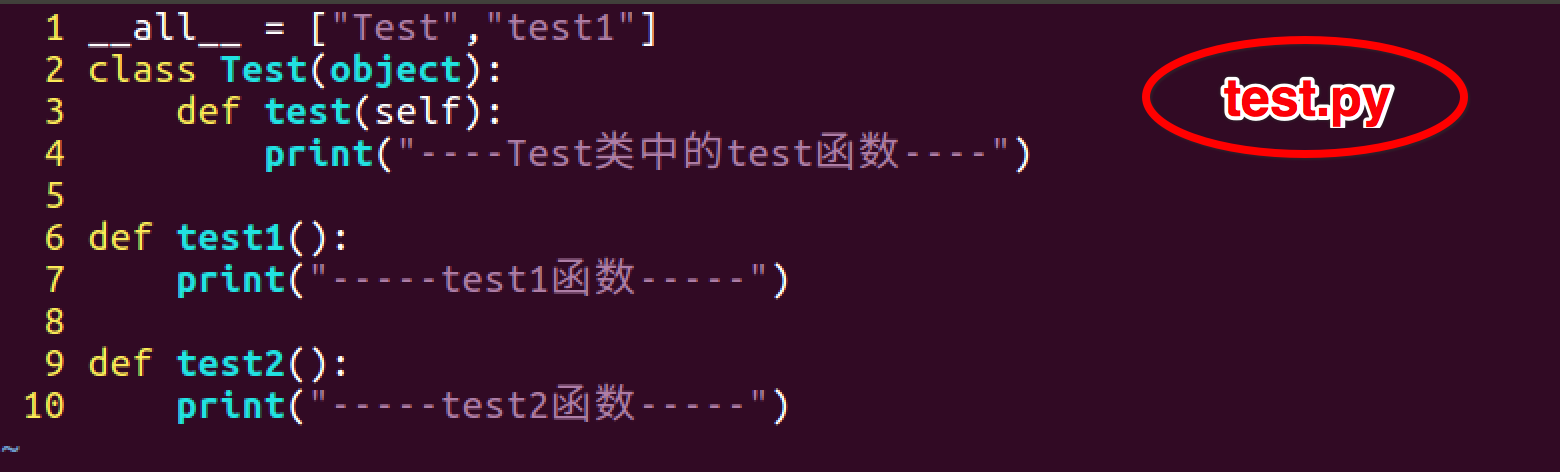
总结
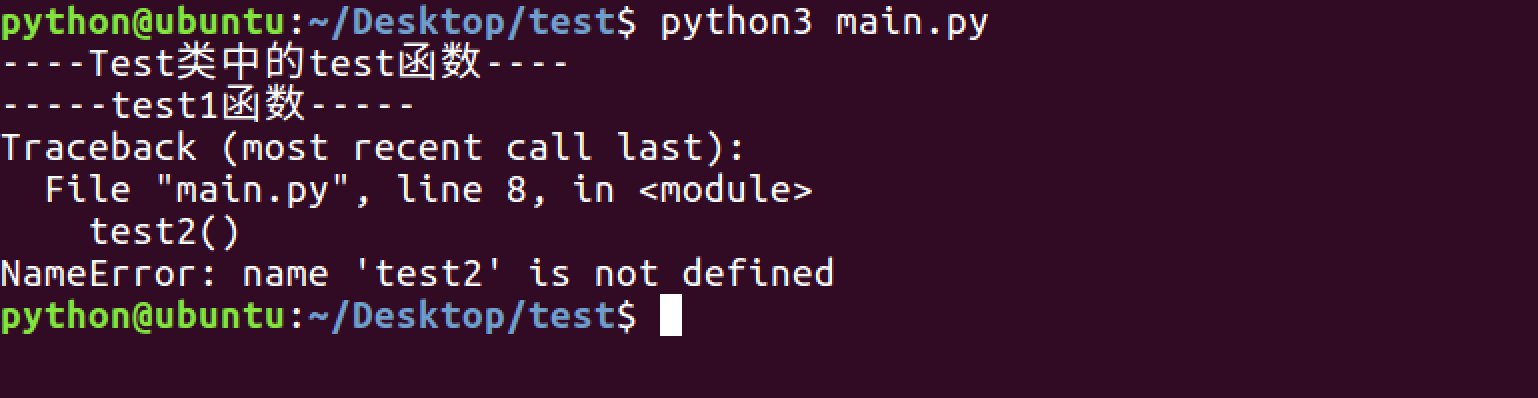
- 如果一个文件中有__all__变量,那么也就意味着这个变量中的元素,不会被from xxx import *时导入
11.9 python中的包
包
1. 引入包
1.1 有2个模块功能有些联系

1.2 所以将其放到同一个文件夹下

1.3 使用import 文件.模块 的方式导入

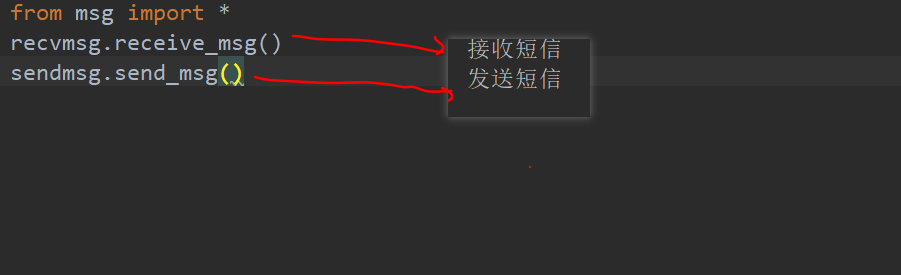
1.4 使用from 文件夹 import 模块 的方式导入

报错无法这样使用
1.5 在msg文件夹下创建__init__.py文件

1.6 在__init__.py文件中写入

1.7 重新使用from 文件夹 import 模块 的方式导入
总结:
- 包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为
__init__.py文件,那么这个文件夹就称之为包 - 有效避免模块名称冲突问题,让应用组织结构更加清晰
2. __init__.py文件有什么用
__init__.py 控制着包的导入行为
2.1 __init__.py为空
仅仅是把这个包导入,不会导入包中的模块
2.2 __all__
在__init__.py文件中,定义一个__all__变量,它控制着 from 包名 import *时导入的模块
2.3 可以在__init__.py文件中编写内容
可以在这个文件中编写语句,当导入时,这些语句就会被执行
__init__.py文件 

2.4 如下导入会报错
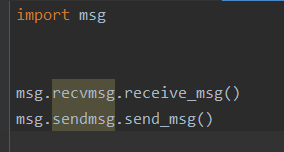

1 | Traceback (most recent call last): |
- 原因:如果init是空的,直接import包的话,不会导入里面的模块
在init中添加代码:
1 | from . import recvmsg |
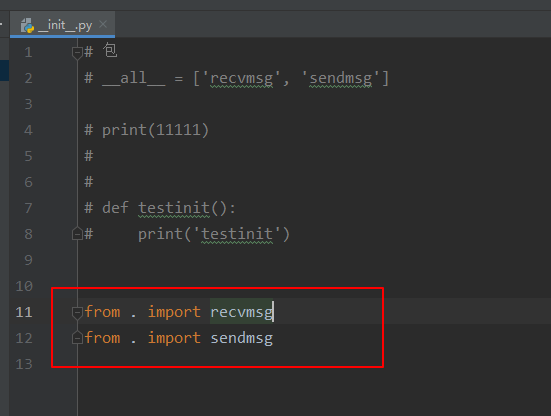
- 然后发现可以正常运行了
3.
python3中,如果init.py文件内容是空的,也不需要在里面写代码,那么可以不用添加init.py,但python2不行

